Have you ever stopped an IIS application pool, just to find it running later? This a quick post to explain why this happens, and how to correctly stop the app pool so it stays down.
(check our Reset, Restart and Recycle IIS guide for more on effectively restarting your application pools and avoiding the problematic side effects).
Why stop an application pool in the first place?
You may choose to stop one of your app pools if:
It’s having an excessive impact on your server.
It is hosting applications that you don’t want running (unused, broken, or for security reasons).
It’s a copy of another application that’s already running (and you don’t want it conflicting or running twice).
You are doing a performance test on another app, and you want everything else stopped.
You are updating the applications and you don’t want them restarting during the update.
Stopping apppools for security and performance reasons can actually be an effective strategy when dealing with many customers/apps on the server, or removing unused applications that can become a DOS target.
Why does the stopped application pool come back to life?
The reason for this is simple. The Windows Process Activation Service (WAS, WPAS) will start all application pools when it starts.
So, if WAS restarts for any reason, it will re-start your stopped application pools.
This will happen in all of these cases:
IISRESET
Net stop was /yes && net start w3svc (restarting IIS services)
Rebooting your server VM
When someone makes a request to the application that’s mapped to your application pool, it will then start a worker process.
The application pool will also start a worker process when using the AlwaysRunning mode. Which we totally recommend for your important production sites, as you can see in our Maximize IIS Application pool availability guide.
How do I stop the pool so it stays stopped?
Easy.
You must also configure the application pool to set autoStart=false. This way, WAS knows not to start it unless you explicitly choose to start it.
Here is the compact command:
%windir%\system32\inetsrv\appcmd set apppool POOLNAME /autoStart:false
%windir%\system32\inetsrv\appcmd stop apppool POOLNAME
This causes this applicationHost.config configuration to be written in your application pool’s definition:
<add name="TestApp" autoStart="false" ...>
To start the application pool back up
If and when you want to get the pool started back up:
%windir%\system32\inetsrv\appcmd set apppool POOLNAME /autoStart:true
%windir%\system32\inetsrv\appcmd start apppool POOLNAME
You can skip the autoStart:true command if you want to continue manually managing the pool’s uptime, and just start/stop it when needed.
That’s it. No more zombie application pools.
P.S. If you haven’t already, check out our Reset, Restart, Recycle IIS guide for useful tips on how to correctly restart production apppools with minimum downtime.
But what you may not know is that when it fails, it often leaves your IIS services in a downed state. Meaning your web server is now permanently down.
You may be using IISRESET as a last resort to fix a website performance issue … but instead you take your entire web server down… Probably not what you intended!
Don’t use IISRESET to fix performance issues … actually fix them instead!
If you are relying on IISRESET to resolve hangs or high CPU, check out our Reset, Restart and Recycle IIS guide for better case-by-case alternatives.
Then, use LeanSentry to diagnose and actually resolve your performance issues so you don’t have to keep restarting as a bandaid.
IISRESET fails with Access Denied (and leaves IIS stopped)
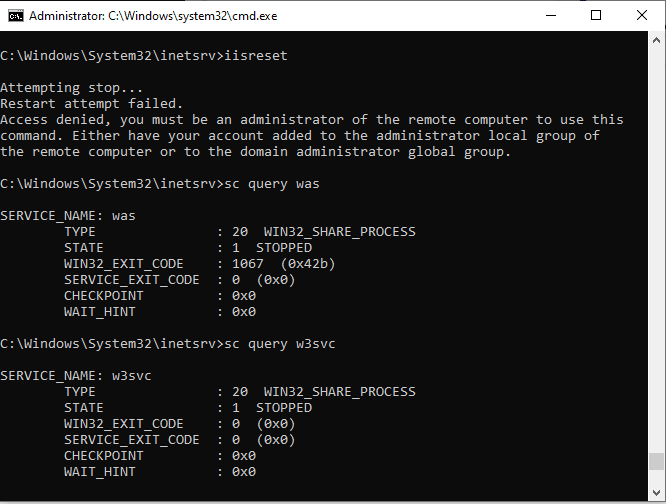
The most common reason why the command fails to restart IIS services, is the frustrating Access Denied error. This happens even when you are executing IISRESET from an elevated “As Administrator” command line:
IISRESET fails to restart IIS and leaves the WAS and W3SVC services stopped
When this happens, you get this error:
Attempting stop...
Stop attempt failed.
Access denied, you must be an administrator of the remote computer to use this command. Either have your account added to the administrator local group of the remote computer or to the domain administrator global group.
This confusing error is actually due to IISRESET timing out when attempting to stop the Windows Process Activation Service (WAS), which probably happens more than 50% of the time.
This is entirely due to the discrepancy between the IISRESET restart timeout (a short 20 seconds) and the default shutdownTimeLimit for IIS worker processes which is 90 seconds by default.
So, this happens:
IISRESET tries to stop WAS.
WAS tells all IIS worker processes to stop, and begins to wait up to 90 seconds for each.
Each worker process tries to wait for any executing requests to finish, which may take anywhere from 0 to 90 seconds (because the process will be killed after that).
IISRESET times out waiting for WAS to stop, and tries to kill it.
This throws the “Access Denied” error.
IISRESET reports the error and bails, without trying to restart IIS services!
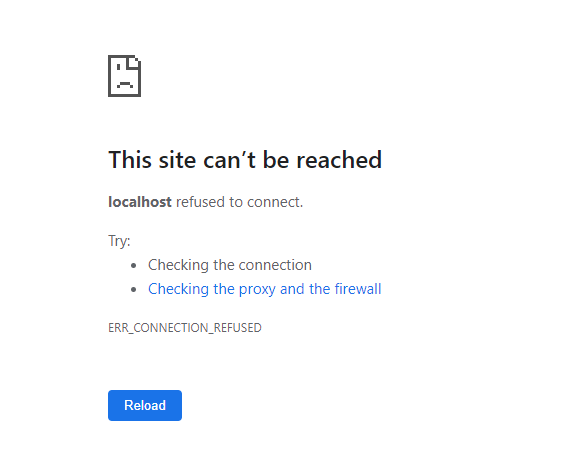
Seconds later, your WAS and W3SVC services are stopped and your webserver is now down. Any traffic to your website is now getting connection refused:
ERR_CONNECTION_REFUSED in chrome because W3SVC removed your websites bindings when it stopped.
You may attempt a quick fix for that IISRESET command:
IISRESET /TIMEOUT:100
This should do it in 90% of cases, but if WAS does legitimately get hung and fail to stop (we’ve never seen that ourselves, but hey it could happen), you are going to get Access Denied again and the services will be left stopped.
IISRESET NOFORCE is a no-go
We also DON’T recommend the NOFORCE option despite what some Microsoft support content out there suggests, for the same reason … because IISRESET /NOFORCE won’t try to kill the services if they are stuck, and they could get left in a bad state.
If you use the NOFORCE parameter, you may also get these errors:
There was an error while performing this operation.
The service cannot accept control messages at this time. (2147943461, 80070425)
or:
Restart attempt failed.
The service cannot accept control messages at this time. (2147943461, 80070425)
So, if I absolutely have to give you a better IISRESET command, here it is:
This makes sure that if WAS does not stop in the reasonable 100 seconds, we kill its host process (this will be the worst case because we are giving enough time for all apppools to stop).
We also make sure the services are terminated if they don’t stop, to avoid leaving them in a bad state.
Then, we always re-start the services! That’s the key part.
How to recover when IISRESET fails
Finally, you just ran IISRESET, and it failed. Your server now may be down.
Recover with these commands:
net stop was /yes
taskkill /F /FI "SERVICES eq was"
net start w3svc
The idea here is that, since we don’t exactly know what state the services are in, we’ll just make sure they are stopped, and then start em clean.
Note that we start W3SVC, NOT WAS. This also starts WAS. Sometimes people forget that you need both, so if you just started WAS, you’d still be getting “This site can’t be reached” errors because the web server would not be listening for any incoming requests to your sites.
That’s it. Now that we recovered your server, be sure to never use IISRESET again. Instead, head over to our Reset, Restart and Recycle IIS guide to learn how to restart your websites with zero downtime.
Other IISRESET errors we’ve seen
Restart attempt failed. The IIS Admin Service or the World Wide Web Publishing Service, or a service dependent on them failed to start. The service, or dependent services, may had an error during its startup or may be disabled.
IISRESET may be failing to start some services that depend on WAS or W3SVC. These services may be disabled or not used on the machine.
Instead of this, just start W3SVC directly with net start w3svc.
Some support content suggests installing or enabling these dependent services to make IISRESET work, but I think that’s completely backwards. If you don’t use those services, why do you have to enable them just to make a broken command work?
Access denied, you must be an administrator of the remote computer to use this command. Either have your account added to the administrator local group of the remote computer or to the domain administrator global group.
This happens because you are trying to run IISRESET from an non-elevated command line, so it’s blocked by User Access Control (UAC). Run the command from a command line prompt started with “As Administrator” instead.
We’ve just released our new IIS Threading guide, which explains how the IIS thread pool works and how it affects your website performance.
It turns out that many people don’t have a clear sense of how the IIS thread pool relates to hangs and slowdowns in their website.
So, we took the opportunity to clear things up, and explain how IIS thread pool exhaustion or thread starvation actually affects IIS site performance.
This includes:
503 Queue Full errors, or application pool queue buildup
Reduced RPS, especially for high performance websites
We also explain how most traditional hangs and slow loads are NOT caused by IIS threadpool issues, but instead the application-specific thread pools like the CLR thread pool, or the Classic ASP thread pool.
Monitoring IIS thread performance
We also show a simple way to monitor IIS counters to detect IIS pool issues.
If you have LeanSentry installed on the server, you can get a lot deeper into actually diagnosing most thread pool issues down to code (part of our application pool failure diagnostics). We’ll cover this well.
LeanSentry diagnosing an 503 queue full incident down to code causing CPU overload, which is then causing IIS thread delays.
Optimizing the thread pool
In the guide, we dig into the specific causes of threading issues, that actually happen. This is based on monitoring 30K+ IIS websites with LeanSentry in the last decade.
Surprisingly, there are only a couple causes of thread pool issues that matter.
We’ll cover each one, and how to configure the IIS threadpool to resolve them.
Start in 100%-warm state, for best cold-start performance (even after a production restart or recycle)
Have zero startup delay (despite the warmup we just mentioned)
Yes, basically you CAN have your cake and eat it too.
Meaning your website is always warm, and can recycle without the users feeling it. This requires getting a lot of pieces right, and guide shows you exactly how to do that.
Best of all, it requires ZERO code.
Configure it all instantly with the ConfigureWarmup tool
We have a tool that will automatically configure the warmup configuration for your website. We’ll be releasing this tool shortly, but if you want it now, be sure to sign up for the Guide newsletter early access. This will allow you to get all our guides, and tools, before they are publicly released online.
We also discuss in detail WHEN you should restart IIS or recycle your application pool, and when you shouldn’t … and the better alternatives to restarting.
Improving IIS application pool availability
This post is part 1 of our upcoming series on how to configure IIS for maximum availability. The next guide will touch on how to configure your sites for 100% warm operation, with zero startup delays. We also have a tool called ConfigureWarmup that can do this for you automatically, and can even test your warmup performance. Stay tuned for these coming in the next two weeks.
P.S. Be sure to sign up for the IIS guides newsletter to get early access to all of these.
It’s hard to believe that LeanSentry is turning 10!
During the last 10 years, we went from a collection of IIS troubleshooting tools that Mike wrote to help fix performance problems for large IIS sites like MySpace, Microsoft mobile, and Vevo to a comprehensive diagnostic service for troubleshooting and optimizing IIS websites.
What’s more, we’ve worked with thousands of companies and IT/developer pros like you to help solve real issues for real applications.
During this time, the number one challenge we’ve heard from our customers is the need for best-practice knowledge, and real-world skills on how to do troubleshooting and optimization. Even with a diagnostic service like LeanSentry, many customers still found it difficult to make the actual changes they needed to resolve their problems.
Get the guides
We personally worked with, and helped thousands of you to do this. Now, we’ll be sharing our techniques and tools we’ve used through the years to empower as many people as possible to run reliable, high performance websites on the Microsoft web platform.
We’ll cover topics like:
How to configure your IIS website for maximum availability,
How to save cloud hosting costs with smart optimizations,
What kind of IIS monitoring helps you fix website issues, and what is a waste of your time,
How to quickly recover from memory leaks, hangs, high CPU issues, queueing, and others,
Best practice application patterns ASP.NET developers can use to build faster, more reliable, more scalable apps,
Tools we use to all these things correctly, and much more…
We’ll also look at a bunch of things that DON’T WORK. There are a lot of those … including popular things that take down your website, break your webserver, or cause you to spend 4x more money on your cloud hosting.
To be the first to receive content, be sure to head over to https://www.leansentry.com/guide and sign up for the Guide newsletter.
You might not know it, but 2017 has been a big year at LeanSentry.
Over the last 5 years, we’ve helped over 10,000 customers take control of production issues in their Microsoft web stack. All the while, we’ve been flying “under the radar” while working out the kinks in our product and our business model.Continue reading Year in Review 2017
Have you ever had an Azure instance that just was not performing up to your expectations?
We have. And in the past, they were very hard to get rid of without affecting your entire cloud deployment.
How-To: Remove Azure instances that became slow or unhealthy
In this week’s How-To post, we’ll cover the new API that lets us easily remove an Azure instance that is performing poorly or has become unhealthy. We also share a tool we wrote to automate the removal, so you can remove dead Azure instances quickly whenever you need.
Back when we launched LeanSentry 2 years ago, we had a lot of issues with Azure instances not performing up to our expectations. In particular, the Azure host processes would die whenever the instances experienced high memory utilization from our custom cache layer, and begin to constantly recycle the role/reboot the VM. This caused service outages during times of peak usage.
Back then, the only way to take an instance out of rotation was to do VIP swap, or to scale down the service to a point where the offending instance would be removed (and so would all other instances with higher instance ids). Because we maintained a lot of in-memory and on-disk state on the instance, both of those options would be a huge no-no. So, we lobbied Microsoft to create an option to remove a specific instance, instead of trashing half of your service.
The Azure team came through and finally released an API to do this. This has been a godsend, allowing us to intelligently manage how we scale up and down so we can keep the instances with the highest efficiency / warmest cache.
For more on how to when to do this, and a tool to quickly delete instances, check out the How-To post here.