In the last 2 years, we’ve helped thousands of big and small companies to improve their IIS servers & ASP.NET applications.
Today, we are announcing LeanSentry How-To: a series of best-practice guides to help you solve common performance problems & improve your site health.
We’ll cover topics like:
1. Azure best practices
2. IIS & ASP.NET performance
3. Improving application & server stability
4. Advanced tools & techniques for troubleshooting production problems
Automatic hang diagnostics for IIS & ASP.NET apps has been one of LeanSentry’s most popular features.
Now, Hang diagnostics are getting even better, with more expert insight into hangs, better root cause detection, and more code-level data for your developers.
Automatically diagnose ASP.NET hangs
LeanSentry’s Hang diagnostics feature helps you resolve your website’s slowdowns, better than you can with generic monitoring tools. It does this by detecting and by automatically diagnosing dozens of common IIS, ASP.NET, and Classic ASP performance problems whenever your site experiences them.
No intrusive profilers, DebugDiag, or other tools needed. Like most of LeanSentry, hang diagnostics have virtually zero overhead during normal operation, and only a small overhead (5-10 seconds of analysis) when a problem is confirmed. This means you can add LeanSentry’s deep diagnostic insight to your existing monitoring without any conflicts or performance drops.
What’s new?
A lot! We’ve improved the diagnostic algorithms to detect more problems. Then there is the brand new diagnostic report interface that gives you better guidance, and more information on what caused the hangs.
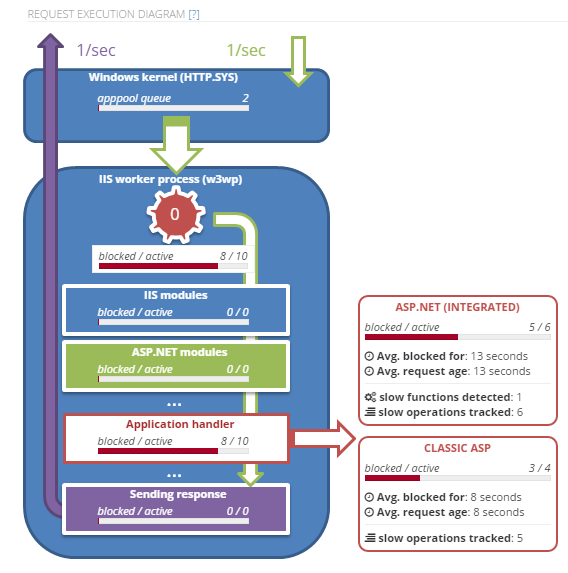
See the actual IIS & ASP.NET operation
See the actual request flow, and the key IIS & ASP.NET performance issues during the hang.
Expert guidance
LeanSentry analyzes the specific causes of the hang in your app, and gives you best practice guidance on how to address it.
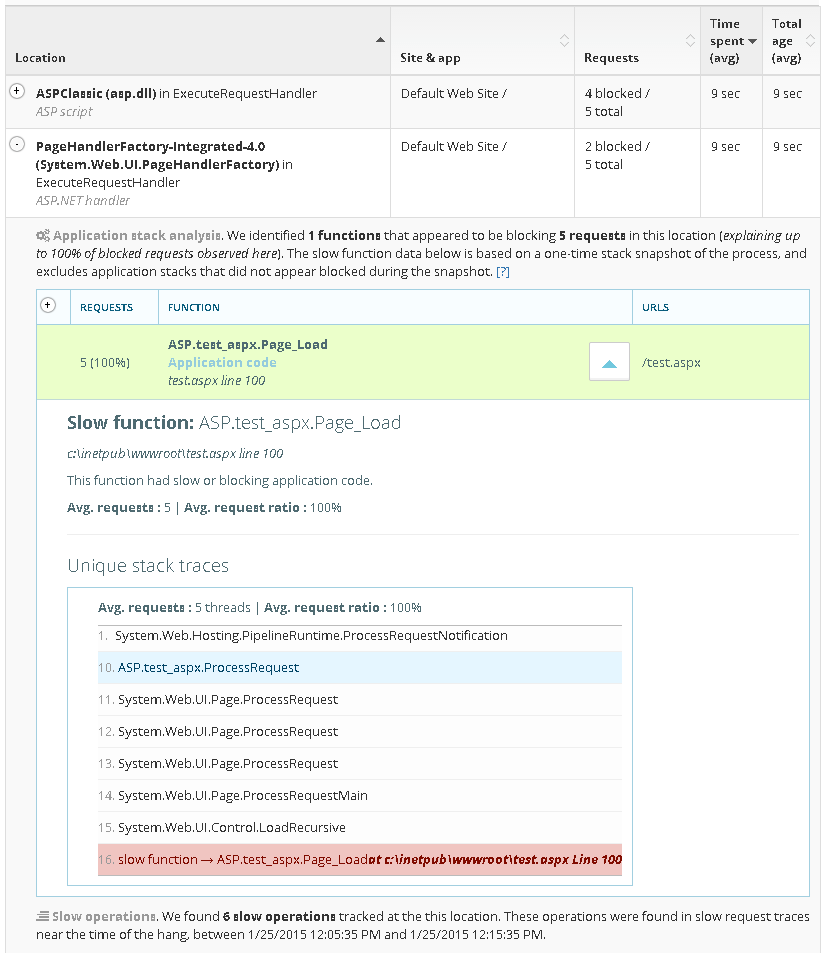
Identify the function, slow SQL, REST call causing blocking
LeanSentry automatically determines the application code causing request blocking or thread pool exhaustion, and shows your the line of code, SQL query, REST url, or file being accessed.
Try it out
If you are still troubleshooting hangs the hard way, or trying to use the generic transaction monitoring tools, you are missing out. To learn more, check out LeanSentry’s hang diagnostics, and do a trial to see it for yourself.
Running production web applications is a constant struggle. Slow page loads, hangs, crashes, memory leaks.
Even when you think you are clear, they come back anytime there is a code change, new feature, new server environment, or even a change in traffic.
You can have the best monitoring system in place, but when the red light goes off … YOU still have to diagnose and fix the problem.
Conveniently, that’s where your monitoring tool politely bows out and lets you do the hard work.
And where many IT and devops teams end up spending most of their time.
At LeanSentry, we set out to fix the production troubleshooting process.
To do it, we had to solve the problem of both tools AND expertise.
Tools. The tools we use fall into two categories: production monitoring tools (perfmon, logparser, SCOM, third parties), and developer analysis tools (debuggers, profilers). The monitoring tools detect but cant diagnose problems. When you finally bring in the heavy developer tools to solve the problem, its already long gone. You can’t profile a process that doesn’t have high CPU anymore … or debug a hang that’s no longer there. The alternative: to run your process under 24/7 profiling and debugger in anticipation of possible problems is just not acceptable.
Expertise. Even if you somehow got all the data, making sense of it can be very difficult. If you’ve ever done a production hang or memory leak investigation, you know exactly how much work and time it takes to get to the bottom of things.
Of course, you could go out and hire an troubleshooting expert. Get security access for them. Spend hours explaining your application to them. Pay them a lot of money. Then, they’ll set up the same debugging tools on your server, wait for the issue to reproduce, and maybe get you the answer several weeks later.
We’ve been doing this kind of troubleshooting for years.
But to make it accessible to everyone who runs Microsoft web apps, we needed to do it automatically, with low overhead, and without requiring the user to be an IIS expert.
Here was our blueprint:
Lightweight 24/7 monitoring to always catch problems the first time. We use performance counters, IIS logs, and ETW events to watch for problems. These protocols have near-zero overhead on the server, and cannot affect the application because they completely external.
Automatically detect problems like hangs or memory leaks. These are the tricks of the trade: rules based on Microsoft guidelines and our own troubleshooting techniques. Our hang diagnostic uses over 12 different rules to reliably detect a hang given various pieces of lightweight monitoring data.
Automatically analyze the problem so you don’t have to. When the problem is detected, we’ll analyze it immediately and attempt to determine the root cause. This also works to eliminate the knowledge gap: software can do the complex analysis and present the facts simply so that operations teams can easily act or transition the resolution to the developer.To do the analysis, we can leverage multiple data sources at our disposal: including IIS logs, ETW events, profiling data, and sometimes the debugger. We’ve been doing this kind of troubleshooting for years, so this was just a matter of automating it.Best of all, this analysis has low impact because a) it only takes place when there is already a problem and b) usually lasts just a few seconds and always keeps the application running.
Alert you about the problem, and show you the solution. This is the best part. Instead of having to spend days hunting and analyzing the problem, you get a shrink-wrapped report with a pretty bow on it (bow not included). This is the difference between taking weeks to diagnose a problem every time, or literally minutes.
LeanSentry can now diagnose: website hangs, ASP.NET memory leaks, IIS application pool crashes, and more
Getting these kind of diagnostics to work right for everyone takes time. We are now 7 months after our launch in February, and here are the kinds of things we can diagnose:
Hangs and slow page loads. We’ll detect IIS website hangs or very slow page loads, and tell you when you have concurrency misconfiguration problems or thread pool exhaustion. Down to the line of code thats causing the hang. Learn more about the hang diagnostic →
IIS and ASP.NET errors, IIS application pool crashes and recycles, and more.
There is too many to list here, but you can see many of them in action in our demo application.
Our ultimate goal was to change the way people deal with application problems in production.
To break the monitor -> struggle -> reproduce -> investigate cycle.
It looks like we are finally doing it. To check out our new diagnostics and how they work, go to www.leansentry.com. While there, set up a free trial account and never look back.
Did you know there are 5 places where ASP.NET requests can become queued on an IIS server?
Not all these queues are documented, and it can be very difficult to tell when and where requests are queued.
As part of LeanSentry’s automatic hang detection and troubleshooting, we had to figure out the IIS/ASP.NET request queueing behavior. So, we wanted to share the knowledge with everyone so you can properly track down queued requests.
Read on to learn all about these queues, how to tell when requests are queued, and how to identify the exact requests that are actually queued!
(UPDATE: Want to learn how to troubleshoot common ASP.NET issues like hangs, high CPU, etc? Take our new LeanSentry Production Troubleshooting course. Its a free 5-7 email course that teaches the production troubleshooting techniques we’ve been using for years.)
The details on IIS and ASP.NET queues
When a request is received by your IIS server, here are all the queues it must clear in order to be processed:
1. HTTP.SYS: Application pool queue
Requests are always first queued here, for the IIS worker process to dequeue.
Behavior: Requests begin to accumulate when IIS falls behind in dequeueing requests. The limit is set by the application pool’s configured queueLength attribute, and defaults to 1000. When limit is reached, HTTP.SYS returns 503 Service Unavailable.
Monitor: “Http Service Request QueuesCurrentQueueSize” performance counter
2. IIS worker process: completion port
The dequeued requests queue up here, waiting for IIS i/o threads to pick them up.
Behavior: There is usually up to 20 possible requests queued here, and they are dispatched up to N at a time (where N = number of processor cores).
Monitor: This is an undocumented queue, with no available reporting.
3. ASP.NET: CLR threadpool queue
ASP.NET queues all incoming requests to the CLR threadpool.
Behavior: If all CLR threads are busy, requests can queue up here up to the configured processModel/requestQueueLimit. When there are more than this many total requests (executing + queued), ASP.NET returns 503 Service Unavailable.
NOTE: Any async modules also re-post requests to the CLR threadpool, so requests can become “re-queued” again later in the request processing.
NOTE: This counter is global for the entire server, there is no way to tell which website/apppool has queued requests. It also does not work correctly in Integrated mode for .NET 2.0/3.5.
4. ASP.NET: Integrated mode global queue
In Integrated mode, ASP.NET will queue all incoming requests after the configured concurrency limit is reached.
Behavior: Concurrency limit is set by the MaxConcurrentRequestsPerCPU registry key or applicationPool/maxConcurrentRequestsPerCPU attribute (Defaults to 12 on .NET 2.0/3.5, and 5000 on .NET 4.0+) and MaxConcurrentThreadsPerCPU registry key or the applicationPool/MaxConcurrentThreadsPerCPU attribute (defaults to 0, disabled).
In Classic mode, ASP.NET will queue all incoming requests to the per-application queue when there are not enough threads.
Behavior: The threads available for request processing are determined by available threads in the CLR thread pool, minus the reserved threads set by the httpRuntime/minFreeThreads and httpRuntime/minFreeLocalThreads attributes.
NOTE: This queue has poor performance, and does not guarantee FIFO in application pools with multiple applications (because threads are shared between multiple apps, so a single app can starve the other applications of available threads).
Monitor: “ASP.NET ApplicationsRequests in Application Queue” performance counter, with instances per application.
How to tell which requests are queued
Ok, so we can now tell whether requests are queued, but how we can tell which requests are queued vs. which requests are processing?
This helps us identify which requests are causing blocking in the system (and possibly causing a hang), vs. the requests that are simply queued as a result.
Well, we can’t tell which requests are queued in queues 1 & 2, because they have not yet been picked up by IIS. We also cant tell which requests are queued in the Classic mode per-application queue. Lucky for us, most queueing for ASP.NET apps in Integrated mode (default) happens in queue #3 and #4. And while we can’t always determine his 100%, there is a heuristic that can help us separated queued from processing requests 90% of the time. In my experience, that has been good enough!
Here is the trick:
1. Snapshot the currently executing requests
> %windir%system32inetsrvappcmd list requests /elapsed:1000
A group of requests to an Integrated pipeline ASP.NET app are queued if they are:
Processing in an ASP.NET module
There are no other requests to the same app in an ASP.NET module in an earlier pipeline stage
There are no other requests to the same app in a different ASP.NET module/stage with higher avg. latency.
Basically, this takes advantage of the fact that the first ASP.NET module in the request processing pipeline will cause ASP.NET to queue the request, showing it as processing in that module in the executing request list. The request at the front of the list have been executing the longest, which means they are NOT queued (queueing is FIFO).
Practically, this just means that the last block of requests in the list the same ASP.NET module/stage are queued requests. Think about it. From experience, these usually show as blocks of:
Simply because for most ASP.NET apps, WindowsAuthentication is the first ASP.NET module to process the request in the AuthenticateRequest stage. If you have a custom module or global.asax processing BeginRequest, expect to see that.
We hope this will help you make sense of queued requests when troubleshooting slow or hung ASP.NET requests.
When you investigate IIS or ASP.NET errors in production, does IIS sometimes feel like a black box?
Learn to use these 4 server logs, and you will always find the error you are looking for.
Its gotta be here somewhere
Finding the error is actually fairly straightforward once you know where to look. Most of the time, the error will be in one of these 4 logfiles by default:
1. First stop: the IIS log
The website’s IIS log will contain an entry for every request to the site. This log is typically located in c:inetpublogsLogFilesW3SVC[SITEID]. For each logged request, the log includes the URL, querystring, and the response status and substatus codes that describe the error:
Tip: Notice the 500 16 0? These are the HTTP response status code, the IIS substatus code, and the win32 error code. You can almost always map the status and substatus code to an error condition listed in IIS7 HTTP error codes. You can also look up the win32 error code via winerror.h.
Is the substatus code 0, esp. 500.0? Then its most likely an application error i.e. ASP.NET, ASP, PHP, etc.
2. Nothing in the IIS log? Check the HTTPERR log
Sometimes, the request will not listed in the IIS log. First make sure that IIS logs are enabled for the website.
In a small percentage of cases, the request may have been rejected by HTTP.SYS before it even made it to an IIS worker process. This generally happens if the request violated the HTTP protocol (client saw HTTP 400: Bad Request) or there was a WAS/the application pool failure (client saw HTTP 503: Service Unavailable).
In this case, you will find the error in the HTTPERR logs, located in c:windowssystem32LogFilesHTTPERR:
Tip: See the Connection_Abandoned_By_ReqQueue? HTTP.SYS is even better than IIS at telling you exactly why the error happened. See HTTP.SYS error codes for the exact cause.
3. ASP.NET exceptions: the Application EventLog
If the request is to an ASP.NET application, and the error was a 500.0, its most likely an unhandled ASP.NET exception. To find it, go to the Application EventLog and look for Warning events from the ASP.NET 4.0.30319.0 or applicable version:
Tip: ASP.NET Health Monitoring will log all errors to the Application EventLog by default. Except 404s. Also, it will only log up to 1 exception per minute. And logging is broken in ASP.NET MVC apps (sigh). Not to worry, here is a way to fix to reliably log ASP.NET exceptions.
4. Hard-to-catch errors: the Failed Request Trace (FRT) log
Can’t seem to catch the error? It it gone from the log before you can get to it? Then you need the IIS Failed Request Trace feature. This will let you configure a rule to capture a detailed request trace for a specific URL, status code, or time elapsed. Learn how to set up Failed Request Tracing to capture IIS errors.
Get ahead of the error game
If you are reacting to user error reports, you are already behind the 8-ball. The reality is, majority of production errors go unreported, because users are reluctant to speak up when they hit problems on your site. Given the short attention spans and low patience these days, they are way more likely to stop using your site instead. By the time you find out you have errors, the damage has already been done.
The only way to really win this game is to get proactive, and continually monitor all errors in your application so you can triage/fix the ones you consider important … BEFORE users begin to notice. If this sounds hard, it doesn’t have to be – esp. if you use LeanSentry’s error monitoring. Give it a try and never worry about hunting for errors again.
404 Not Found is the most common error for most production web applications. So, its all too easy to start ignoring them after a while.
After all, you can’t do anything about pages that don’t exist in your site, right?
WRONG. Turns out, 404 errors often signal real production problems that CAN and SHOULD be fixed.
Problems like:
Broken links to your site that are causing you to lose potential sales or leads
Botched deployment / code changes that prevent your users from using your site correctly
Hacking activity that is wasting significant processing resources on your server
Read on to learn about the 4 common classes of 404 Not Found errors and what you should do to find and fix them.
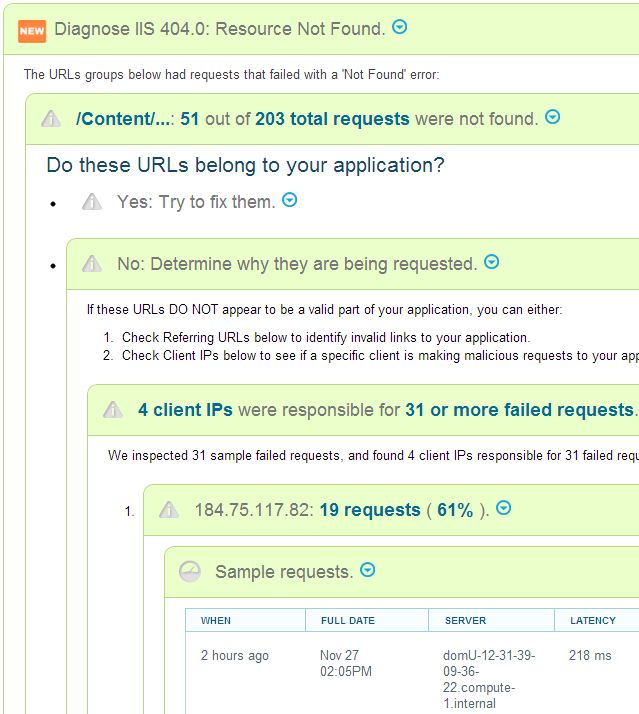
LeanSentry tracks every single IIS and ASP.NET error for thousands of websites, and 404 Not Found is always at the top of the list. In fact, being able to ignore 404 errors has been a top LeanSentry feature request.
We’ve done a lot of work to help people track and fix production errors: grouping related errors, highlighting important errors, and letting the user quickly filter down to the errors they care about. While we dont advocate ignoring errors outright, we are also adding a feature to let you prioritize/hide specific errors for an app or just for a specific server / url.
The 4 classes of 404 errors you probably want to fix
Here are 4 key classes of 404 Not Found errors that require further attention, and how you can fix them:
1. Broken links to your site
Broken links to your site cause you to lose valuable leads, and frustrate your users. In some cases, bad links from major referral sources can cause you to lose a large percentage of your traffic.
How to find it
Look for 404 errors that request URLs that appear to “belong” to your site, e.g. following your site’s URL hierarchy or mispelling known versions of your urls.
How to fix it
Break the 404 errors by URL, and by HTTP Referer. You should be able to identify groups of specific content and referring sites that have the broken links.
NOTE: You need to turn on “Referer” field in your IIS logs to do this. It is unfortunately NOT enabled by default.
If the referrer is your own site, you can fix your own links. If the referrer is a third party site, you can contact them to get their links fixed.
2. Missing content, due to bad deployment or site changes
Bad deployments of your site content can cause some of your important content to become unavailable. Site changes often cause the same problem, esp. when URL rewriting or dynamic routing is involved.
How to find it
Look for 404 errors for URLs that previously worked.
How to fix it
You’ll need to diagnose the cause of the 404 error. This can be hard, since there can be many IIS and ASP.NET problems that lead to 404s (we’ll write another blog post about how to diagnose 404s comprehensively). Here are the top things to check:
1. Try to reproduce the 404 not found error yourself. Request the URL, if it returns a 404, great! You can now troubleshoot the error to figure out why. Be sure to use the detailed error page to confirm what physical file is being requested, and make sure it actually exists on the server.
2. Set up Failed Request Tracing to capture the 404 error trace. In the resulting traces, you should have all the details you need – the requested URL, phsysical resource it mapped to, the associated handler, and the error details.
3. Server routing errors
The server routing errors are becoming a more common problem, since many IIS/ASP.NET applications use SEO-friendly extensionless URLs, and code-determined routing (like ASP.NET MVC routing). A common time for these is a new code deployment or deployed to a new server, which can break both the configuration needed for routing and the code routing rules.
The process for finding and fixing this is similar to #2. However, a more detailed investigation may be required to understand why the routes are not working. The Failed Request Trace of the request may be a good start since it can trace URL Rewriter rule matching, and handler mapping done as part of routing. Also see this post for debugging ASP.NET MVC routing problems.
4. Hacking attempts
Many 404 errors are the result of hacking or bots scanning your website for vulnerabilities. I am sure everyone with a production website has seen the ubiquitous requests to “php_myadmin” even if they don’t have any PHP content.
You may want to dismiss these errors as “nothing you can do”. However, consider the following before moving on:
1. Requests to missing content can add significant processing overhead to your server. For example, they can cause worker processes to be started and ASP.NET applications to be loaded into memory / performing expensive initialization (this can be a big problem for servers that host many inactive applications).
2. Hacker requests failing with 404 not found errors may be a precursor to successful hacking attempts. You may want to stop them before its too late.
How to find it
Break down your 404 errors by URL, and look for URLs that do not appear to be a legitimate part of your application. Specifically, look for URLs that have never been successfully requested.
Then, break down the 404 errors by client IP, by HTTP referer, and by User Agent. You will often be able to spot traffic from specific clients, or specific user agents, and this traffic will almost never have the HTTP referer set (be careful with jumping to conclusons if you dont have HTTP referer logging enabled).
How to fix it
To eliminate the impact of the traffic on your server, and to prevent hacking attempts, block the traffic you identify as malicious. Here are the top ideas:
1. Deny access to folders with authorization rules.
The best way to keep your website healthy is to watch the errors you have in production. Any time you see an increase in errors, or an increase in a specific error, you should investigate to see if there is a problem that can be fixed. By contrast, not watching errors or hoping that they will go away is a quick way to lose sales and frustrate your users.
Users don’t complain, they just leave. This was a lesson we learned early on after launching LeanSentry. After our initial launch, we had a ton of errors due to load problems with our backend. Once in a while, a user complained about the errors, and we fixed them.
However, eventually we realized that many users were just getting frustrated and leaving the site, without ever telling us about it.
So, we implemented a proactive strategy where we watched every single error, and followed up with every user that ever hit one. This helped us understand the true scale of the problems, fix them, and make sure that we stopped frustrated users from leaving.
LeanSentry is one great way to keep tabs on production errors in your IIS/ASP.NET applications. It tracks every single error, and groups related errors to give you an accurate history of how often the error happens.
What’s more, LeanSentry also solves the problem of troubleshooting the error, by capturing all the details you or your developers need to fix the error. Including ASP.NET exception callstacks, detailed request traces, and more.
LeanSentry tracks down all 404 errors, and walks you through the troubleshooting steps to fix them.
To see how LeanSentry error tracking helps you get a handle on production errors, pop over to www.leansentry.com and check out the live demo! Then set up the free trial and never look back.
TechEd is awesome! Its our first major conference, and so far the reception has been great. You can really tell that LeanSentry is addressing a major pain point for pretty much everyone running the IIS/ASP.NET application stack.
TechEd is definitely more of an enterprise crowd, with attendees ranging from midsize companies to the likes of Deloitte and Verizon. However, they face many of the same problems that we see in small businesses and startups. Turns out production troubleshooting is a great equalizer 🙂
Things you loved!
It’s been great to get some face-to-face feedback about LeanSentry. Here are a few of the highlights that everyone absolutely loved:
1. IIS hang and crash diagnostics. This was literally jaw-dropping for some. We asked if debugging hangs in production was a problem, and you could just see the pain in people’s eyes. The best response we got was “Its the difference between a good day and a bad day”.
People just could not believe that LeanSentry could diagnose a hang automatically, and get them right to the source of the hang in a few clicks.
2. Lightweight monitoring, with no profilers / nothing to install on the production servers. This was a huge hit. It was clear that you appreciated non-intrusive monitoring that doesnt slow down your applications with a profiler.
And of course, everyone loved the LeanSentry Robot! We’ve had attendees say that it was the best t-shirt at the conference. If you didn’t get the shirt at the booth, email us and we may be able to mail you one.
Things you wanted
We’ve also gotten a good sense for what people want to see from LeanSentry. The big one was a self-hosted version of LeanSentry that can be deployed in environments compliant with PCI, HIPAA, and defense contractor requirements. We heard you loud and clear on that, and we can say that a version of self-hosted LeanSentry is in the works.
If you want to use the self-hosted version of LeanSentry, email us and we can discuss the timeframe further.
TechEd continues, so if you are there be sure to come by booth 2417 today and check us out.
It’s your peak traffic hour, and your website is not loading. Requests are timing out, and recycling the application pool isn’t helping this time.
We’ve all been there, and it’s a nightmare even for a seasoned IIS/ASP.NET pro.
Website hangs are an unfortunate but common reality for web applications. To make things worse, even the latest and greatest performance monitoring products don’t help. After 10 years in this business, we don’t know a single commercial or MSFT tool that can figure out what causes a hang in an IIS / ASP.NET application (more on why later). So, this is where the seasoned pro reaches for the hardcore tools, the WinDbg debugger or Debug Diagnostics … and mentally prepares to spend hours digging around. That is, if they are are lucky enough to catch the problem live on a machine with the debugger installed.
And what if you don’t make a living debugging IIS? Call Microsoft support and get ready to spend 15 hours on the phone before you can get someone who even knows what a w3wp dump is. We’ve had difficult hangs take 2 months to resolve, between catching and collecting proper evidence for a hang in production, and waiting for MSFT support to escalate to an engineer that knows what they are doing.
It’s no wonder that it took us this long to finally tackle this scenario with LeanSentry. There are just so many things that can go wrong: hanging SQL or web service calls, application deadlocks, thread pool exhaustion (in both the IIS and CLR threadpools), CPU overload, the list just goes on. Most of the time, many of these things cascade together to cause the hang.
That said, we finally did it. LeanSentry is now the only monitoring tool available that automatically troubleshoots IIS/ASP.NET hangs.
This is how it works:
1. Your website encounters a hang for one out of dozen possible reasons.
2. LeanSentry automatically detects the hang, performs a realtime diagnostic test, and sends you an alert that tells you exactly what caused the hang.
This makes sure that we capture the hang no matter when, how rarely, or on what server the hang happened. LeanSentry then tries to cut through the complexity of the hang analysis, and explain what happened in plain language so you can quickly understand and take action to resolve it.
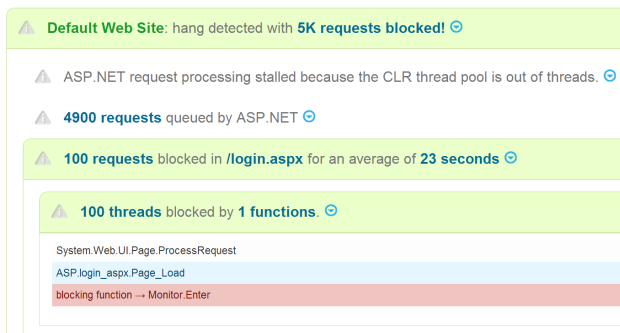
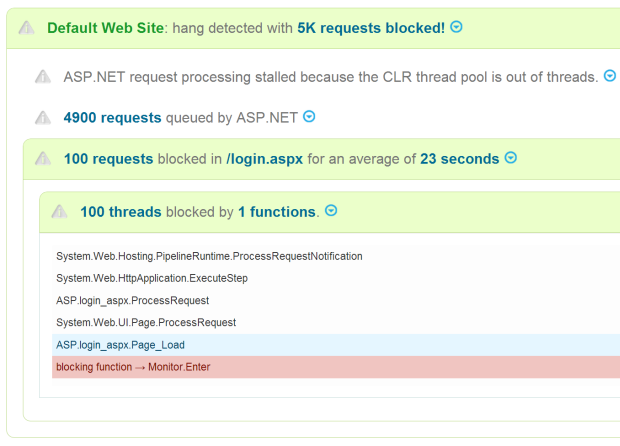
LeanSentry breaks down a hang simply: ASP.NET fell behind in request processing with 4900 requests in the queue, because it ran out of threads in the CLR threadpool. The 100 threads available were blocked waiting for the 100 requests that got stuck in Page_Load() in login.aspx.
Sounds too good to be true, right? We thought so too when we finally got it to work. Here is what happens in more detail:
1. Realtime hang detection without debuggers. LeanSentry continuously monitors each application pool for signs of hangs, to make sure that we catch it whenever it happens. This is done using LeanSentry’s standard lightweight monitoring, which has virtually 0 impact on your production systems, unlike running your applications with a debugger or profiler attached. This also means it can even be done remotely without installing anything on your actual production servers. When detecting a hang, we take into account the application pool’s specific IIS/ASP.NET threading settings that affect request processing, as well as many other known symptoms of hangs. For example, Max Queued Item Age of the application pool queue stably increasing for over 30 seconds. We can’t trust all signs though, so we look at multiple signs together and pick those that most likely indicate hangs or serious perf degradation.
2. Confirm the hang. When a hang is suspected, LeanSentry will snapshot currently executing requests and identify which requests appear queued, or blocked. For example, blocked requests have been executing in the same place for over 10 seconds. Queued requests are hard to identify and require us to use a bunch of heuristics.
3. Determine application functions that are causing blocking. If the executing requests confirm the hang, the LeanSentry Agent will perform a differential thread snapshot of the process, which will determine where threads are stuck in your application code.
4. Diagnose thread pool exhaustion. Finally, we will analyze threading and queueing characteristics of the application pool across the HTTP.SYS kernel queue, IIS, and ASP.NET, and figure out where exhaustion is taking place.
5. Generate the alert. The “Website had hung requests” alert will be generated, you’ll get an email, and can view the alert page for a step-by-step hang diagnosis.
Why aren’t there any other commercial tools that diagnose IIS/ASP.NET hangs?
Because its very hard to do. Don’t believe me? Try to follow the explanation of how ASP.NET thread pool behaves between Integrated and Classic mode across .NET 3.5. 3.5 SP1, and 4.0. It will make your brain sad. To make things even worse, recent versions of ASP.NET broke a lot of the more obscure but documented queueing functionality (MaxConcurrentRequestsPerCPU = 0 no longer works by default, and the “ASP.NET ApplicationsRequests Executing” counter erroneously shows “total requests served” instead). This shows that even the product teams at Microsoft are not closely following this area of the platform.
The only MSFT tool that even tries to diagnose hangs is the Debug Diagnostics tool, which is not suitable for continuous production monitoring and only diagnoses a small subset of issues that cause hangs. The tool itself is showing its age, having been built internally in Microsoft for pre-.NET applications and only recently adding very partial support for .NET. In most of today’s applications, hangs involve .NET applications and the .NET CLR thread pool.
Third party profiler-based APM tools that support the Microsoft platform, like New Relic or AppDynamics, lack the Windows and IIS-specific intelligence needed to diagnose these problems. They may help you pinpoint slow code (but usually not during a hang because requests never complete), but will not be able to understand what happens under the covers of IIS/ASP.NET runtimes that triggers the hang. These tools also come with the overhead of running your production applications under a profiler, which has a heavier overhead than most people are willing to allow.
Getting it done
The step-by-step Hang diagnosis will walk you through the hang as it happened, showing you where requests are blocked up to the application function, and even the HTTP request or SQL query it was making.
The diagnosis will also determine if IIS/ASP.NET threading configurations are causing the problem, and recommend adjustments for the workload.
Keep in mind, because LeanSentry performs hang detection and diagnosis in realtime, you can watch how changes in your configuration and code cause hang-type problems over time, and get up-to-date recommendations on how to avoid them. This is very different from hiring an IIS expert or Microsoft to diagnose a hang for you, because you’ll at best get the resolution for the point in time problem – which may or may not help you the next time.
The automatic hang diagnostics is one of the best examples of how LeanSentry improves your experience of running Microsoft web apps, by combining lightweight 24×7 monitoring with expert analysis based on 10 years of solving these problems for hundreds of companies. You need both: to catch the problem in production, and to make sure you can make heads or tails of it later.
Think of LeanSentry as your resident IIS expert – one that never sleeps, and costs pennies compared to what it costs to hire comparable experts from the outside. If you haven’t tried it already, sign up for the trial, and take control over hangs and other production problems with LeanSentry’s automated production diagnostics.