It’s hard to believe that LeanSentry is turning 10!
During the last 10 years, we went from a collection of IIS troubleshooting tools that Mike wrote to help fix performance problems for large IIS sites like MySpace, Microsoft mobile, and Vevo to a comprehensive diagnostic service for troubleshooting and optimizing IIS websites.
What’s more, we’ve worked with thousands of companies and IT/developer pros like you to help solve real issues for real applications.
During this time, the number one challenge we’ve heard from our customers is the need for best-practice knowledge, and real-world skills on how to do troubleshooting and optimization. Even with a diagnostic service like LeanSentry, many customers still found it difficult to make the actual changes they needed to resolve their problems.
Get the guides
We personally worked with, and helped thousands of you to do this. Now, we’ll be sharing our techniques and tools we’ve used through the years to empower as many people as possible to run reliable, high performance websites on the Microsoft web platform.
We’ll cover topics like:
How to configure your IIS website for maximum availability,
How to save cloud hosting costs with smart optimizations,
What kind of IIS monitoring helps you fix website issues, and what is a waste of your time,
How to quickly recover from memory leaks, hangs, high CPU issues, queueing, and others,
Best practice application patterns ASP.NET developers can use to build faster, more reliable, more scalable apps,
Tools we use to all these things correctly, and much more…
We’ll also look at a bunch of things that DON’T WORK. There are a lot of those … including popular things that take down your website, break your webserver, or cause you to spend 4x more money on your cloud hosting.
To be the first to receive content, be sure to head over to https://www.leansentry.com/guide and sign up for the Guide newsletter.
You might not know it, but 2017 has been a big year at LeanSentry.
Over the last 5 years, we’ve helped over 10,000 customers take control of production issues in their Microsoft web stack. All the while, we’ve been flying “under the radar” while working out the kinks in our product and our business model.Continue reading Year in Review 2017
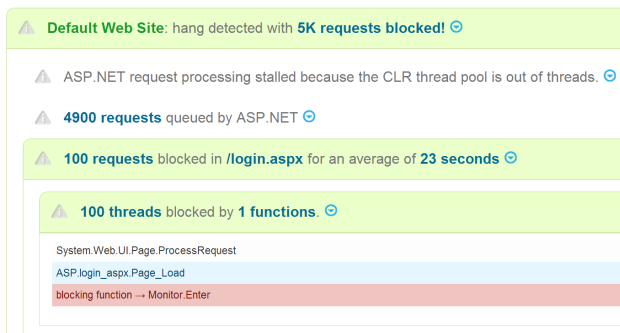
Automatic hang diagnostics for IIS & ASP.NET apps has been one of LeanSentry’s most popular features.
Now, Hang diagnostics are getting even better, with more expert insight into hangs, better root cause detection, and more code-level data for your developers.
Automatically diagnose ASP.NET hangs
LeanSentry’s Hang diagnostics feature helps you resolve your website’s slowdowns, better than you can with generic monitoring tools. It does this by detecting and by automatically diagnosing dozens of common IIS, ASP.NET, and Classic ASP performance problems whenever your site experiences them.
No intrusive profilers, DebugDiag, or other tools needed. Like most of LeanSentry, hang diagnostics have virtually zero overhead during normal operation, and only a small overhead (5-10 seconds of analysis) when a problem is confirmed. This means you can add LeanSentry’s deep diagnostic insight to your existing monitoring without any conflicts or performance drops.
What’s new?
A lot! We’ve improved the diagnostic algorithms to detect more problems. Then there is the brand new diagnostic report interface that gives you better guidance, and more information on what caused the hangs.
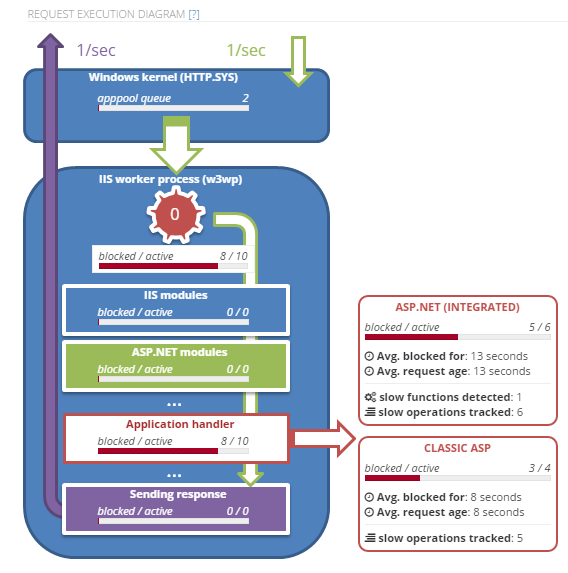
See the actual IIS & ASP.NET operation
See the actual request flow, and the key IIS & ASP.NET performance issues during the hang.
Expert guidance
LeanSentry analyzes the specific causes of the hang in your app, and gives you best practice guidance on how to address it.
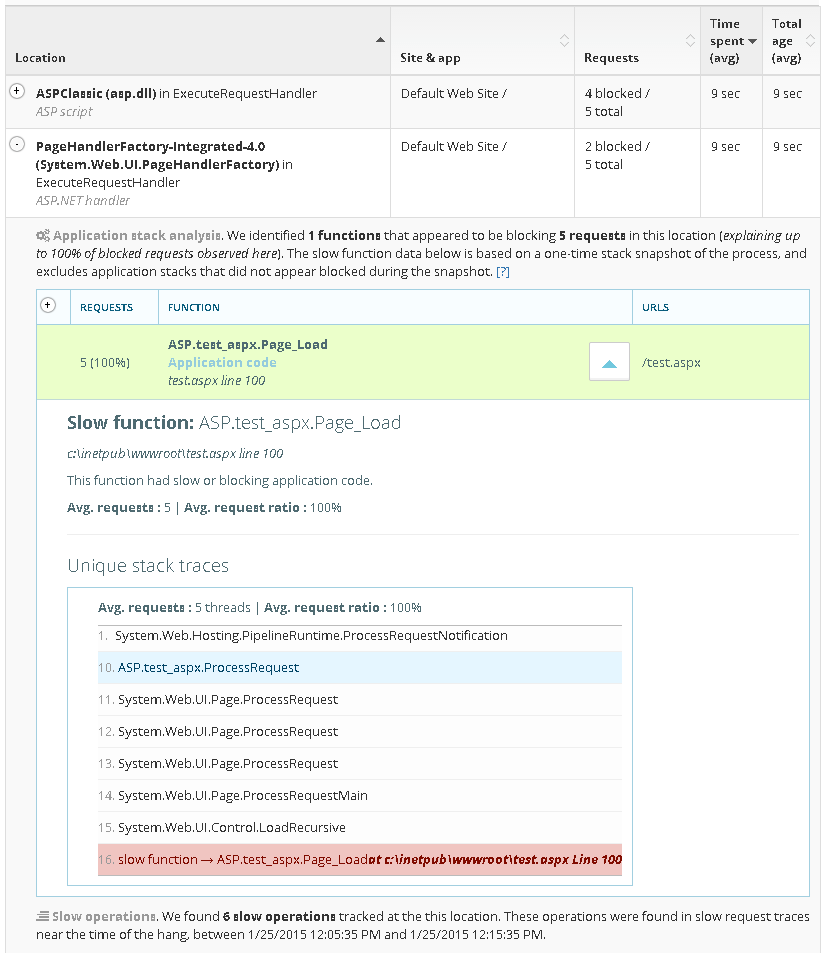
Identify the function, slow SQL, REST call causing blocking
LeanSentry automatically determines the application code causing request blocking or thread pool exhaustion, and shows your the line of code, SQL query, REST url, or file being accessed.
Try it out
If you are still troubleshooting hangs the hard way, or trying to use the generic transaction monitoring tools, you are missing out. To learn more, check out LeanSentry’s hang diagnostics, and do a trial to see it for yourself.
You may have noticed that we’ve been very quiet in the last year. The reason: as a small team, we found the initial demand for LeanSentry a bit overwhelming. This made it difficult to focus on building the kind of product we envisioned.
So, we decided to take a year to innovate our product, and deliver the kind of experience that our customers wanted.
Today, we are back with a brand new www.leansentry.com and whole new generation of our service.
What does LeanSentry do?
LeanSentry uses expert analysis techniques, many developed at Microsoft, to give you deeper insight into your web apps.
We automatically analyze IIS and ASP.NET performance, troubleshoot website hangs, tune .NET CPU and memory usage, troubleshoot errors, and much more.
The best part? It’s lightweight, cannot affect your applications, and can run alongside any existing APM or monitoring tool.
What’s different about LeanSentry?
In short, everything!
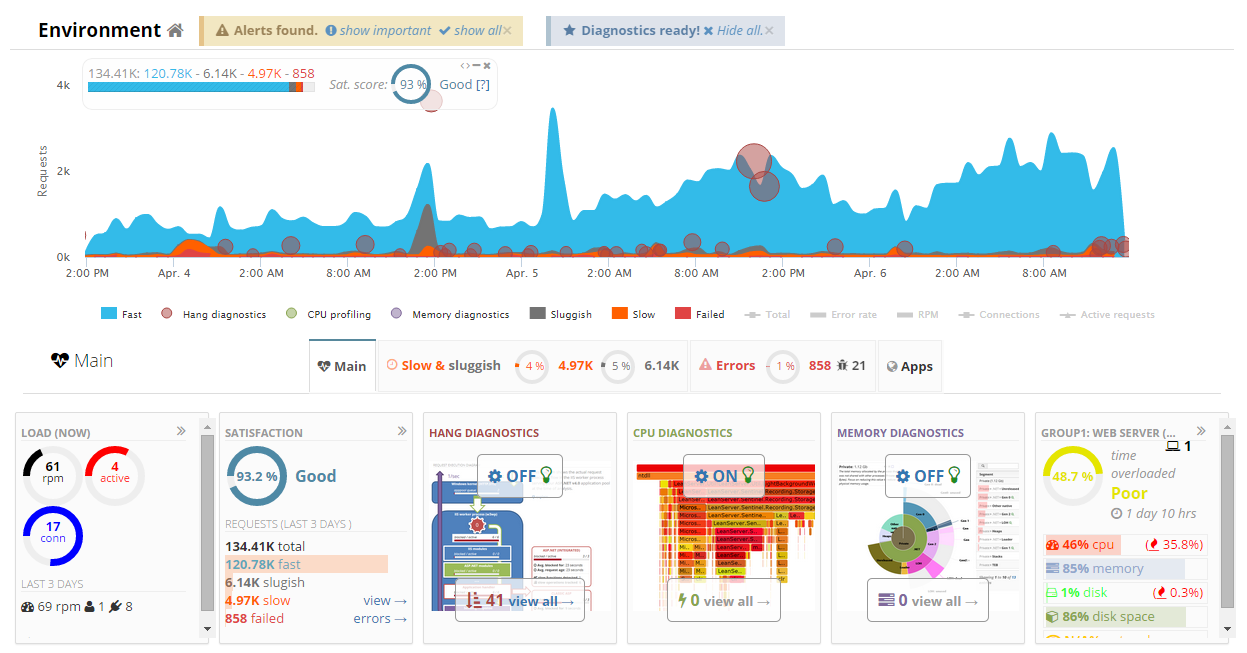
We have a brand new, real-time interface that makes it easy to access information with just a few clicks.
Our diagnostics have been upgraded to be way easier, and give you lot a lot more insight into your stack’s performance.
We have a simpler, faster deployment that lets you add LeanSentry to your production servers, Windows Azure or Amazon EC2 in less than 5 minutes, with no restarts or iisreset.
Here are some highlights for a quick glance:
Use hang diagnostics to see what causes IIS & ASP.NET performance problems in your site.
Quickly resolve memory leaks and tune the application’s memory usage.
Automatically analyze CPU usage if your website consumes high CPU.
Get code-level details to tune application CPU usage.
Identify blocking application functions that cause hangs and slow requests.
Detect most production problems and get the diagnostics to resolve them quickly.
Give me!
If you’ve tried LeanSentry a while back, you simply must see it again.
If you have not, this is a good time to check it out! Head over to www.leansentry.com and sign up for the free trial to see for yourself.
To all our customers and everyone that supported us so far, thank you! We hope the new service makes your life that much better. Stay tuned for a lot more about the new product, our story, and much more in the coming weeks!
AppliedInnovations, a leading Windows hosting provider, announced a partnership with LeanSentry to help customers get their Windows web apps ready for the holiday rush.
It did so after getting requests from its customers who have already been finding LeanSentry incredibly helpful.
Says Mayer Kahan, owner of Osgood Textiles at www.onlinefabricstore.net:
“We are a .NET shop, troubleshooting bugs has always been a time consuming process of code review and digging through server logs.
LeanSentry finally allowed us to see in real time how our site is performing, providing a single platform for viewing our whole environment.
As a result, we improved site performance, and were able to be better informed about what is really going on with our physical environment.”
If you are an AppliedInnovations customer, it has never been a better time to try LeanSentry.
If not, you can get your trial account now at https://www.leansentry.com/. If you are running an ecommerce site on the Windows platform, this just might be a smart move for the Black Friday/Chrismas season.
This week, we have another big improvement for you.
We completely remade our Performance page, and made it a lot easier to view your website performance data.
What’s there?
Slow requests tab shows you what operations caused slow requests to your site.
Resource use tab shows you the CPU, Memory, and Network usage by the website … compare it across all servers … and give you the diagnostic data to explain what caused the usage.
As a bonus, you can enable CPU profiling, Memory diagnostics, and slow operation tracking directly from the page.
Above all, the new interface is clean and wonderfully simple.
This is available immediately in your LeanSentry account! Just log in and go to the Performance page for any of your websites.
Running production web applications is a constant struggle. Slow page loads, hangs, crashes, memory leaks.
Even when you think you are clear, they come back anytime there is a code change, new feature, new server environment, or even a change in traffic.
You can have the best monitoring system in place, but when the red light goes off … YOU still have to diagnose and fix the problem.
Conveniently, that’s where your monitoring tool politely bows out and lets you do the hard work.
And where many IT and devops teams end up spending most of their time.
At LeanSentry, we set out to fix the production troubleshooting process.
To do it, we had to solve the problem of both tools AND expertise.
Tools. The tools we use fall into two categories: production monitoring tools (perfmon, logparser, SCOM, third parties), and developer analysis tools (debuggers, profilers). The monitoring tools detect but cant diagnose problems. When you finally bring in the heavy developer tools to solve the problem, its already long gone. You can’t profile a process that doesn’t have high CPU anymore … or debug a hang that’s no longer there. The alternative: to run your process under 24/7 profiling and debugger in anticipation of possible problems is just not acceptable.
Expertise. Even if you somehow got all the data, making sense of it can be very difficult. If you’ve ever done a production hang or memory leak investigation, you know exactly how much work and time it takes to get to the bottom of things.
Of course, you could go out and hire an troubleshooting expert. Get security access for them. Spend hours explaining your application to them. Pay them a lot of money. Then, they’ll set up the same debugging tools on your server, wait for the issue to reproduce, and maybe get you the answer several weeks later.
We’ve been doing this kind of troubleshooting for years.
But to make it accessible to everyone who runs Microsoft web apps, we needed to do it automatically, with low overhead, and without requiring the user to be an IIS expert.
Here was our blueprint:
Lightweight 24/7 monitoring to always catch problems the first time. We use performance counters, IIS logs, and ETW events to watch for problems. These protocols have near-zero overhead on the server, and cannot affect the application because they completely external.
Automatically detect problems like hangs or memory leaks. These are the tricks of the trade: rules based on Microsoft guidelines and our own troubleshooting techniques. Our hang diagnostic uses over 12 different rules to reliably detect a hang given various pieces of lightweight monitoring data.
Automatically analyze the problem so you don’t have to. When the problem is detected, we’ll analyze it immediately and attempt to determine the root cause. This also works to eliminate the knowledge gap: software can do the complex analysis and present the facts simply so that operations teams can easily act or transition the resolution to the developer.To do the analysis, we can leverage multiple data sources at our disposal: including IIS logs, ETW events, profiling data, and sometimes the debugger. We’ve been doing this kind of troubleshooting for years, so this was just a matter of automating it.Best of all, this analysis has low impact because a) it only takes place when there is already a problem and b) usually lasts just a few seconds and always keeps the application running.
Alert you about the problem, and show you the solution. This is the best part. Instead of having to spend days hunting and analyzing the problem, you get a shrink-wrapped report with a pretty bow on it (bow not included). This is the difference between taking weeks to diagnose a problem every time, or literally minutes.
LeanSentry can now diagnose: website hangs, ASP.NET memory leaks, IIS application pool crashes, and more
Getting these kind of diagnostics to work right for everyone takes time. We are now 7 months after our launch in February, and here are the kinds of things we can diagnose:
Hangs and slow page loads. We’ll detect IIS website hangs or very slow page loads, and tell you when you have concurrency misconfiguration problems or thread pool exhaustion. Down to the line of code thats causing the hang. Learn more about the hang diagnostic →
IIS and ASP.NET errors, IIS application pool crashes and recycles, and more.
There is too many to list here, but you can see many of them in action in our demo application.
Our ultimate goal was to change the way people deal with application problems in production.
To break the monitor -> struggle -> reproduce -> investigate cycle.
It looks like we are finally doing it. To check out our new diagnostics and how they work, go to www.leansentry.com. While there, set up a free trial account and never look back.
Did you know there are 5 places where ASP.NET requests can become queued on an IIS server?
Not all these queues are documented, and it can be very difficult to tell when and where requests are queued.
As part of LeanSentry’s automatic hang detection and troubleshooting, we had to figure out the IIS/ASP.NET request queueing behavior. So, we wanted to share the knowledge with everyone so you can properly track down queued requests.
Read on to learn all about these queues, how to tell when requests are queued, and how to identify the exact requests that are actually queued!
(UPDATE: Want to learn how to troubleshoot common ASP.NET issues like hangs, high CPU, etc? Take our new LeanSentry Production Troubleshooting course. Its a free 5-7 email course that teaches the production troubleshooting techniques we’ve been using for years.)
The details on IIS and ASP.NET queues
When a request is received by your IIS server, here are all the queues it must clear in order to be processed:
1. HTTP.SYS: Application pool queue
Requests are always first queued here, for the IIS worker process to dequeue.
Behavior: Requests begin to accumulate when IIS falls behind in dequeueing requests. The limit is set by the application pool’s configured queueLength attribute, and defaults to 1000. When limit is reached, HTTP.SYS returns 503 Service Unavailable.
Monitor: “Http Service Request QueuesCurrentQueueSize” performance counter
2. IIS worker process: completion port
The dequeued requests queue up here, waiting for IIS i/o threads to pick them up.
Behavior: There is usually up to 20 possible requests queued here, and they are dispatched up to N at a time (where N = number of processor cores).
Monitor: This is an undocumented queue, with no available reporting.
3. ASP.NET: CLR threadpool queue
ASP.NET queues all incoming requests to the CLR threadpool.
Behavior: If all CLR threads are busy, requests can queue up here up to the configured processModel/requestQueueLimit. When there are more than this many total requests (executing + queued), ASP.NET returns 503 Service Unavailable.
NOTE: Any async modules also re-post requests to the CLR threadpool, so requests can become “re-queued” again later in the request processing.
NOTE: This counter is global for the entire server, there is no way to tell which website/apppool has queued requests. It also does not work correctly in Integrated mode for .NET 2.0/3.5.
4. ASP.NET: Integrated mode global queue
In Integrated mode, ASP.NET will queue all incoming requests after the configured concurrency limit is reached.
Behavior: Concurrency limit is set by the MaxConcurrentRequestsPerCPU registry key or applicationPool/maxConcurrentRequestsPerCPU attribute (Defaults to 12 on .NET 2.0/3.5, and 5000 on .NET 4.0+) and MaxConcurrentThreadsPerCPU registry key or the applicationPool/MaxConcurrentThreadsPerCPU attribute (defaults to 0, disabled).
In Classic mode, ASP.NET will queue all incoming requests to the per-application queue when there are not enough threads.
Behavior: The threads available for request processing are determined by available threads in the CLR thread pool, minus the reserved threads set by the httpRuntime/minFreeThreads and httpRuntime/minFreeLocalThreads attributes.
NOTE: This queue has poor performance, and does not guarantee FIFO in application pools with multiple applications (because threads are shared between multiple apps, so a single app can starve the other applications of available threads).
Monitor: “ASP.NET ApplicationsRequests in Application Queue” performance counter, with instances per application.
How to tell which requests are queued
Ok, so we can now tell whether requests are queued, but how we can tell which requests are queued vs. which requests are processing?
This helps us identify which requests are causing blocking in the system (and possibly causing a hang), vs. the requests that are simply queued as a result.
Well, we can’t tell which requests are queued in queues 1 & 2, because they have not yet been picked up by IIS. We also cant tell which requests are queued in the Classic mode per-application queue. Lucky for us, most queueing for ASP.NET apps in Integrated mode (default) happens in queue #3 and #4. And while we can’t always determine his 100%, there is a heuristic that can help us separated queued from processing requests 90% of the time. In my experience, that has been good enough!
Here is the trick:
1. Snapshot the currently executing requests
> %windir%system32inetsrvappcmd list requests /elapsed:1000
A group of requests to an Integrated pipeline ASP.NET app are queued if they are:
Processing in an ASP.NET module
There are no other requests to the same app in an ASP.NET module in an earlier pipeline stage
There are no other requests to the same app in a different ASP.NET module/stage with higher avg. latency.
Basically, this takes advantage of the fact that the first ASP.NET module in the request processing pipeline will cause ASP.NET to queue the request, showing it as processing in that module in the executing request list. The request at the front of the list have been executing the longest, which means they are NOT queued (queueing is FIFO).
Practically, this just means that the last block of requests in the list the same ASP.NET module/stage are queued requests. Think about it. From experience, these usually show as blocks of:
Simply because for most ASP.NET apps, WindowsAuthentication is the first ASP.NET module to process the request in the AuthenticateRequest stage. If you have a custom module or global.asax processing BeginRequest, expect to see that.
We hope this will help you make sense of queued requests when troubleshooting slow or hung ASP.NET requests.
When you investigate IIS or ASP.NET errors in production, does IIS sometimes feel like a black box?
Learn to use these 4 server logs, and you will always find the error you are looking for.
Its gotta be here somewhere
Finding the error is actually fairly straightforward once you know where to look. Most of the time, the error will be in one of these 4 logfiles by default:
1. First stop: the IIS log
The website’s IIS log will contain an entry for every request to the site. This log is typically located in c:inetpublogsLogFilesW3SVC[SITEID]. For each logged request, the log includes the URL, querystring, and the response status and substatus codes that describe the error:
Tip: Notice the 500 16 0? These are the HTTP response status code, the IIS substatus code, and the win32 error code. You can almost always map the status and substatus code to an error condition listed in IIS7 HTTP error codes. You can also look up the win32 error code via winerror.h.
Is the substatus code 0, esp. 500.0? Then its most likely an application error i.e. ASP.NET, ASP, PHP, etc.
2. Nothing in the IIS log? Check the HTTPERR log
Sometimes, the request will not listed in the IIS log. First make sure that IIS logs are enabled for the website.
In a small percentage of cases, the request may have been rejected by HTTP.SYS before it even made it to an IIS worker process. This generally happens if the request violated the HTTP protocol (client saw HTTP 400: Bad Request) or there was a WAS/the application pool failure (client saw HTTP 503: Service Unavailable).
In this case, you will find the error in the HTTPERR logs, located in c:windowssystem32LogFilesHTTPERR:
Tip: See the Connection_Abandoned_By_ReqQueue? HTTP.SYS is even better than IIS at telling you exactly why the error happened. See HTTP.SYS error codes for the exact cause.
3. ASP.NET exceptions: the Application EventLog
If the request is to an ASP.NET application, and the error was a 500.0, its most likely an unhandled ASP.NET exception. To find it, go to the Application EventLog and look for Warning events from the ASP.NET 4.0.30319.0 or applicable version:
Tip: ASP.NET Health Monitoring will log all errors to the Application EventLog by default. Except 404s. Also, it will only log up to 1 exception per minute. And logging is broken in ASP.NET MVC apps (sigh). Not to worry, here is a way to fix to reliably log ASP.NET exceptions.
4. Hard-to-catch errors: the Failed Request Trace (FRT) log
Can’t seem to catch the error? It it gone from the log before you can get to it? Then you need the IIS Failed Request Trace feature. This will let you configure a rule to capture a detailed request trace for a specific URL, status code, or time elapsed. Learn how to set up Failed Request Tracing to capture IIS errors.
Get ahead of the error game
If you are reacting to user error reports, you are already behind the 8-ball. The reality is, majority of production errors go unreported, because users are reluctant to speak up when they hit problems on your site. Given the short attention spans and low patience these days, they are way more likely to stop using your site instead. By the time you find out you have errors, the damage has already been done.
The only way to really win this game is to get proactive, and continually monitor all errors in your application so you can triage/fix the ones you consider important … BEFORE users begin to notice. If this sounds hard, it doesn’t have to be – esp. if you use LeanSentry’s error monitoring. Give it a try and never worry about hunting for errors again.