Have you ever stopped an IIS application pool, just to find it running later? This a quick post to explain why this happens, and how to correctly stop the app pool so it stays down.
(check our Reset, Restart and Recycle IIS guide for more on effectively restarting your application pools and avoiding the problematic side effects).
Why stop an application pool in the first place?
You may choose to stop one of your app pools if:
It’s having an excessive impact on your server.
It is hosting applications that you don’t want running (unused, broken, or for security reasons).
It’s a copy of another application that’s already running (and you don’t want it conflicting or running twice).
You are doing a performance test on another app, and you want everything else stopped.
You are updating the applications and you don’t want them restarting during the update.
Stopping apppools for security and performance reasons can actually be an effective strategy when dealing with many customers/apps on the server, or removing unused applications that can become a DOS target.
Why does the stopped application pool come back to life?
The reason for this is simple. The Windows Process Activation Service (WAS, WPAS) will start all application pools when it starts.
So, if WAS restarts for any reason, it will re-start your stopped application pools.
This will happen in all of these cases:
IISRESET
Net stop was /yes && net start w3svc (restarting IIS services)
Rebooting your server VM
When someone makes a request to the application that’s mapped to your application pool, it will then start a worker process.
The application pool will also start a worker process when using the AlwaysRunning mode. Which we totally recommend for your important production sites, as you can see in our Maximize IIS Application pool availability guide.
How do I stop the pool so it stays stopped?
Easy.
You must also configure the application pool to set autoStart=false. This way, WAS knows not to start it unless you explicitly choose to start it.
Here is the compact command:
%windir%\system32\inetsrv\appcmd set apppool POOLNAME /autoStart:false
%windir%\system32\inetsrv\appcmd stop apppool POOLNAME
This causes this applicationHost.config configuration to be written in your application pool’s definition:
<add name="TestApp" autoStart="false" ...>
To start the application pool back up
If and when you want to get the pool started back up:
%windir%\system32\inetsrv\appcmd set apppool POOLNAME /autoStart:true
%windir%\system32\inetsrv\appcmd start apppool POOLNAME
You can skip the autoStart:true command if you want to continue manually managing the pool’s uptime, and just start/stop it when needed.
That’s it. No more zombie application pools.
P.S. If you haven’t already, check out our Reset, Restart, Recycle IIS guide for useful tips on how to correctly restart production apppools with minimum downtime.
We’ve been working hard on LeanSentry’s automatic diagnostics, to make sure it can detect and diagnose most production issues for you.
If you are not using LeanSentry yet, that means you are still doing troubleshooting by hand. To help, Mike recently created the LeanSentry Production troubleshooting course, an email course based with his own debugging techniques.
The guide gives practical tips on how to isolate, and diagnose the hang so you can fix it. All you’ll need is the standard Microsoft tools and some time.
Here is a sneak peak:
Want more IIS & ASP.NET troubleshooting guides?
If we get good feedback on the guide, we plan to turn the rest of the class into online guides for everyone to use.
It helps us raise our profile, and its an awesome way for us to contribute to the IIS & ASP.NET community.
Did you know there are 5 places where ASP.NET requests can become queued on an IIS server?
Not all these queues are documented, and it can be very difficult to tell when and where requests are queued.
As part of LeanSentry’s automatic hang detection and troubleshooting, we had to figure out the IIS/ASP.NET request queueing behavior. So, we wanted to share the knowledge with everyone so you can properly track down queued requests.
Read on to learn all about these queues, how to tell when requests are queued, and how to identify the exact requests that are actually queued!
(UPDATE: Want to learn how to troubleshoot common ASP.NET issues like hangs, high CPU, etc? Take our new LeanSentry Production Troubleshooting course. Its a free 5-7 email course that teaches the production troubleshooting techniques we’ve been using for years.)
The details on IIS and ASP.NET queues
When a request is received by your IIS server, here are all the queues it must clear in order to be processed:
1. HTTP.SYS: Application pool queue
Requests are always first queued here, for the IIS worker process to dequeue.
Behavior: Requests begin to accumulate when IIS falls behind in dequeueing requests. The limit is set by the application pool’s configured queueLength attribute, and defaults to 1000. When limit is reached, HTTP.SYS returns 503 Service Unavailable.
Monitor: “Http Service Request QueuesCurrentQueueSize” performance counter
2. IIS worker process: completion port
The dequeued requests queue up here, waiting for IIS i/o threads to pick them up.
Behavior: There is usually up to 20 possible requests queued here, and they are dispatched up to N at a time (where N = number of processor cores).
Monitor: This is an undocumented queue, with no available reporting.
3. ASP.NET: CLR threadpool queue
ASP.NET queues all incoming requests to the CLR threadpool.
Behavior: If all CLR threads are busy, requests can queue up here up to the configured processModel/requestQueueLimit. When there are more than this many total requests (executing + queued), ASP.NET returns 503 Service Unavailable.
NOTE: Any async modules also re-post requests to the CLR threadpool, so requests can become “re-queued” again later in the request processing.
NOTE: This counter is global for the entire server, there is no way to tell which website/apppool has queued requests. It also does not work correctly in Integrated mode for .NET 2.0/3.5.
4. ASP.NET: Integrated mode global queue
In Integrated mode, ASP.NET will queue all incoming requests after the configured concurrency limit is reached.
Behavior: Concurrency limit is set by the MaxConcurrentRequestsPerCPU registry key or applicationPool/maxConcurrentRequestsPerCPU attribute (Defaults to 12 on .NET 2.0/3.5, and 5000 on .NET 4.0+) and MaxConcurrentThreadsPerCPU registry key or the applicationPool/MaxConcurrentThreadsPerCPU attribute (defaults to 0, disabled).
In Classic mode, ASP.NET will queue all incoming requests to the per-application queue when there are not enough threads.
Behavior: The threads available for request processing are determined by available threads in the CLR thread pool, minus the reserved threads set by the httpRuntime/minFreeThreads and httpRuntime/minFreeLocalThreads attributes.
NOTE: This queue has poor performance, and does not guarantee FIFO in application pools with multiple applications (because threads are shared between multiple apps, so a single app can starve the other applications of available threads).
Monitor: “ASP.NET ApplicationsRequests in Application Queue” performance counter, with instances per application.
How to tell which requests are queued
Ok, so we can now tell whether requests are queued, but how we can tell which requests are queued vs. which requests are processing?
This helps us identify which requests are causing blocking in the system (and possibly causing a hang), vs. the requests that are simply queued as a result.
Well, we can’t tell which requests are queued in queues 1 & 2, because they have not yet been picked up by IIS. We also cant tell which requests are queued in the Classic mode per-application queue. Lucky for us, most queueing for ASP.NET apps in Integrated mode (default) happens in queue #3 and #4. And while we can’t always determine his 100%, there is a heuristic that can help us separated queued from processing requests 90% of the time. In my experience, that has been good enough!
Here is the trick:
1. Snapshot the currently executing requests
> %windir%system32inetsrvappcmd list requests /elapsed:1000
A group of requests to an Integrated pipeline ASP.NET app are queued if they are:
Processing in an ASP.NET module
There are no other requests to the same app in an ASP.NET module in an earlier pipeline stage
There are no other requests to the same app in a different ASP.NET module/stage with higher avg. latency.
Basically, this takes advantage of the fact that the first ASP.NET module in the request processing pipeline will cause ASP.NET to queue the request, showing it as processing in that module in the executing request list. The request at the front of the list have been executing the longest, which means they are NOT queued (queueing is FIFO).
Practically, this just means that the last block of requests in the list the same ASP.NET module/stage are queued requests. Think about it. From experience, these usually show as blocks of:
Simply because for most ASP.NET apps, WindowsAuthentication is the first ASP.NET module to process the request in the AuthenticateRequest stage. If you have a custom module or global.asax processing BeginRequest, expect to see that.
We hope this will help you make sense of queued requests when troubleshooting slow or hung ASP.NET requests.
When you investigate IIS or ASP.NET errors in production, does IIS sometimes feel like a black box?
Learn to use these 4 server logs, and you will always find the error you are looking for.
Its gotta be here somewhere
Finding the error is actually fairly straightforward once you know where to look. Most of the time, the error will be in one of these 4 logfiles by default:
1. First stop: the IIS log
The website’s IIS log will contain an entry for every request to the site. This log is typically located in c:inetpublogsLogFilesW3SVC[SITEID]. For each logged request, the log includes the URL, querystring, and the response status and substatus codes that describe the error:
Tip: Notice the 500 16 0? These are the HTTP response status code, the IIS substatus code, and the win32 error code. You can almost always map the status and substatus code to an error condition listed in IIS7 HTTP error codes. You can also look up the win32 error code via winerror.h.
Is the substatus code 0, esp. 500.0? Then its most likely an application error i.e. ASP.NET, ASP, PHP, etc.
2. Nothing in the IIS log? Check the HTTPERR log
Sometimes, the request will not listed in the IIS log. First make sure that IIS logs are enabled for the website.
In a small percentage of cases, the request may have been rejected by HTTP.SYS before it even made it to an IIS worker process. This generally happens if the request violated the HTTP protocol (client saw HTTP 400: Bad Request) or there was a WAS/the application pool failure (client saw HTTP 503: Service Unavailable).
In this case, you will find the error in the HTTPERR logs, located in c:windowssystem32LogFilesHTTPERR:
Tip: See the Connection_Abandoned_By_ReqQueue? HTTP.SYS is even better than IIS at telling you exactly why the error happened. See HTTP.SYS error codes for the exact cause.
3. ASP.NET exceptions: the Application EventLog
If the request is to an ASP.NET application, and the error was a 500.0, its most likely an unhandled ASP.NET exception. To find it, go to the Application EventLog and look for Warning events from the ASP.NET 4.0.30319.0 or applicable version:
Tip: ASP.NET Health Monitoring will log all errors to the Application EventLog by default. Except 404s. Also, it will only log up to 1 exception per minute. And logging is broken in ASP.NET MVC apps (sigh). Not to worry, here is a way to fix to reliably log ASP.NET exceptions.
4. Hard-to-catch errors: the Failed Request Trace (FRT) log
Can’t seem to catch the error? It it gone from the log before you can get to it? Then you need the IIS Failed Request Trace feature. This will let you configure a rule to capture a detailed request trace for a specific URL, status code, or time elapsed. Learn how to set up Failed Request Tracing to capture IIS errors.
Get ahead of the error game
If you are reacting to user error reports, you are already behind the 8-ball. The reality is, majority of production errors go unreported, because users are reluctant to speak up when they hit problems on your site. Given the short attention spans and low patience these days, they are way more likely to stop using your site instead. By the time you find out you have errors, the damage has already been done.
The only way to really win this game is to get proactive, and continually monitor all errors in your application so you can triage/fix the ones you consider important … BEFORE users begin to notice. If this sounds hard, it doesn’t have to be – esp. if you use LeanSentry’s error monitoring. Give it a try and never worry about hunting for errors again.
404 Not Found is the most common error for most production web applications. So, its all too easy to start ignoring them after a while.
After all, you can’t do anything about pages that don’t exist in your site, right?
WRONG. Turns out, 404 errors often signal real production problems that CAN and SHOULD be fixed.
Problems like:
Broken links to your site that are causing you to lose potential sales or leads
Botched deployment / code changes that prevent your users from using your site correctly
Hacking activity that is wasting significant processing resources on your server
Read on to learn about the 4 common classes of 404 Not Found errors and what you should do to find and fix them.
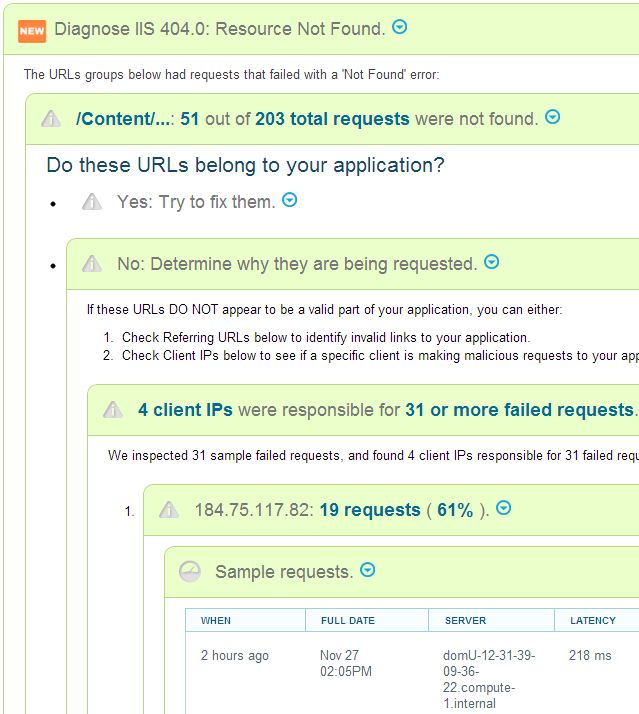
LeanSentry tracks every single IIS and ASP.NET error for thousands of websites, and 404 Not Found is always at the top of the list. In fact, being able to ignore 404 errors has been a top LeanSentry feature request.
We’ve done a lot of work to help people track and fix production errors: grouping related errors, highlighting important errors, and letting the user quickly filter down to the errors they care about. While we dont advocate ignoring errors outright, we are also adding a feature to let you prioritize/hide specific errors for an app or just for a specific server / url.
The 4 classes of 404 errors you probably want to fix
Here are 4 key classes of 404 Not Found errors that require further attention, and how you can fix them:
1. Broken links to your site
Broken links to your site cause you to lose valuable leads, and frustrate your users. In some cases, bad links from major referral sources can cause you to lose a large percentage of your traffic.
How to find it
Look for 404 errors that request URLs that appear to “belong” to your site, e.g. following your site’s URL hierarchy or mispelling known versions of your urls.
How to fix it
Break the 404 errors by URL, and by HTTP Referer. You should be able to identify groups of specific content and referring sites that have the broken links.
NOTE: You need to turn on “Referer” field in your IIS logs to do this. It is unfortunately NOT enabled by default.
If the referrer is your own site, you can fix your own links. If the referrer is a third party site, you can contact them to get their links fixed.
2. Missing content, due to bad deployment or site changes
Bad deployments of your site content can cause some of your important content to become unavailable. Site changes often cause the same problem, esp. when URL rewriting or dynamic routing is involved.
How to find it
Look for 404 errors for URLs that previously worked.
How to fix it
You’ll need to diagnose the cause of the 404 error. This can be hard, since there can be many IIS and ASP.NET problems that lead to 404s (we’ll write another blog post about how to diagnose 404s comprehensively). Here are the top things to check:
1. Try to reproduce the 404 not found error yourself. Request the URL, if it returns a 404, great! You can now troubleshoot the error to figure out why. Be sure to use the detailed error page to confirm what physical file is being requested, and make sure it actually exists on the server.
2. Set up Failed Request Tracing to capture the 404 error trace. In the resulting traces, you should have all the details you need – the requested URL, phsysical resource it mapped to, the associated handler, and the error details.
3. Server routing errors
The server routing errors are becoming a more common problem, since many IIS/ASP.NET applications use SEO-friendly extensionless URLs, and code-determined routing (like ASP.NET MVC routing). A common time for these is a new code deployment or deployed to a new server, which can break both the configuration needed for routing and the code routing rules.
The process for finding and fixing this is similar to #2. However, a more detailed investigation may be required to understand why the routes are not working. The Failed Request Trace of the request may be a good start since it can trace URL Rewriter rule matching, and handler mapping done as part of routing. Also see this post for debugging ASP.NET MVC routing problems.
4. Hacking attempts
Many 404 errors are the result of hacking or bots scanning your website for vulnerabilities. I am sure everyone with a production website has seen the ubiquitous requests to “php_myadmin” even if they don’t have any PHP content.
You may want to dismiss these errors as “nothing you can do”. However, consider the following before moving on:
1. Requests to missing content can add significant processing overhead to your server. For example, they can cause worker processes to be started and ASP.NET applications to be loaded into memory / performing expensive initialization (this can be a big problem for servers that host many inactive applications).
2. Hacker requests failing with 404 not found errors may be a precursor to successful hacking attempts. You may want to stop them before its too late.
How to find it
Break down your 404 errors by URL, and look for URLs that do not appear to be a legitimate part of your application. Specifically, look for URLs that have never been successfully requested.
Then, break down the 404 errors by client IP, by HTTP referer, and by User Agent. You will often be able to spot traffic from specific clients, or specific user agents, and this traffic will almost never have the HTTP referer set (be careful with jumping to conclusons if you dont have HTTP referer logging enabled).
How to fix it
To eliminate the impact of the traffic on your server, and to prevent hacking attempts, block the traffic you identify as malicious. Here are the top ideas:
1. Deny access to folders with authorization rules.
The best way to keep your website healthy is to watch the errors you have in production. Any time you see an increase in errors, or an increase in a specific error, you should investigate to see if there is a problem that can be fixed. By contrast, not watching errors or hoping that they will go away is a quick way to lose sales and frustrate your users.
Users don’t complain, they just leave. This was a lesson we learned early on after launching LeanSentry. After our initial launch, we had a ton of errors due to load problems with our backend. Once in a while, a user complained about the errors, and we fixed them.
However, eventually we realized that many users were just getting frustrated and leaving the site, without ever telling us about it.
So, we implemented a proactive strategy where we watched every single error, and followed up with every user that ever hit one. This helped us understand the true scale of the problems, fix them, and make sure that we stopped frustrated users from leaving.
LeanSentry is one great way to keep tabs on production errors in your IIS/ASP.NET applications. It tracks every single error, and groups related errors to give you an accurate history of how often the error happens.
What’s more, LeanSentry also solves the problem of troubleshooting the error, by capturing all the details you or your developers need to fix the error. Including ASP.NET exception callstacks, detailed request traces, and more.
LeanSentry tracks down all 404 errors, and walks you through the troubleshooting steps to fix them.
To see how LeanSentry error tracking helps you get a handle on production errors, pop over to www.leansentry.com and check out the live demo! Then set up the free trial and never look back.
You can now deploy LeanSentry to your Windows Azure project in just a few keystrokes, by using our Nuget package! This makes deploying to Azure a snap.
Install with:
PM> Install-Package LeanSentryAzureDeployment
As soon as you re-publish your project to Azure normally, LeanSentry will be installed and will begin monitoring the performance and health of your Azure application.
This can make a huge difference, since Azure apps can be so notoriously hard to diagnose when they fail. Esp. when your role keeps recycling due to an unhandled exception or a startup task error – you may not be able to log into your instance, but LeanSentry is running on it and is capturing errors and other interesting events. You can then log into your www.leansentry.com dashboard and troubleshoot from there!
We are excited to see our users trying LeanSentry out over the last few weeks, and have been getting great feedback that make features like this possible. Keep it coming!