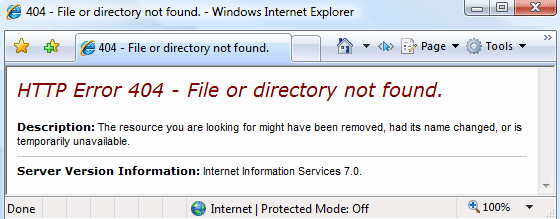
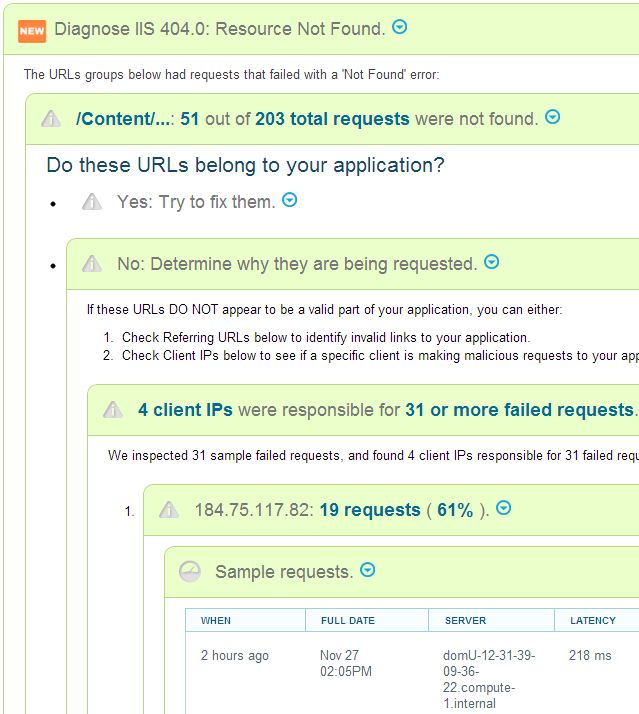
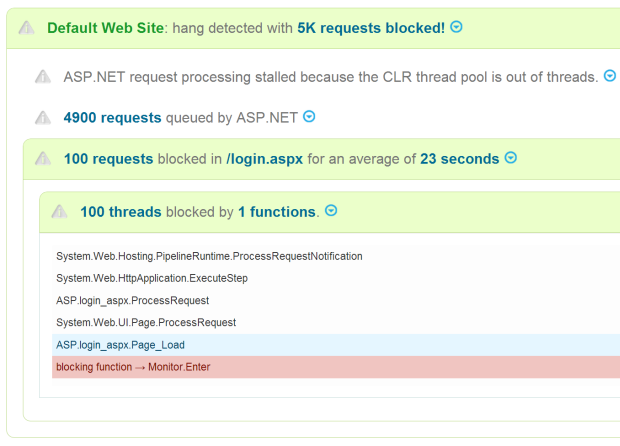
Running production web applications is a constant struggle. Slow page loads, hangs, crashes, memory leaks.
Even when you think you are clear, they come back anytime there is a code change, new feature, new server environment, or even a change in traffic.
You can have the best monitoring system in place, but when the red light goes off … YOU still have to diagnose and fix the problem.
Conveniently, that’s where your monitoring tool politely bows out and lets you do the hard work.
And where many IT and devops teams end up spending most of their time.
At LeanSentry, we set out to fix the production troubleshooting process.
To do it, we had to solve the problem of both tools AND expertise.
Tools. The tools we use fall into two categories: production monitoring tools (perfmon, logparser, SCOM, third parties), and developer analysis tools (debuggers, profilers). The monitoring tools detect but cant diagnose problems. When you finally bring in the heavy developer tools to solve the problem, its already long gone. You can’t profile a process that doesn’t have high CPU anymore … or debug a hang that’s no longer there. The alternative: to run your process under 24/7 profiling and debugger in anticipation of possible problems is just not acceptable.
Expertise. Even if you somehow got all the data, making sense of it can be very difficult. If you’ve ever done a production hang or memory leak investigation, you know exactly how much work and time it takes to get to the bottom of things.
Of course, you could go out and hire an troubleshooting expert. Get security access for them. Spend hours explaining your application to them. Pay them a lot of money. Then, they’ll set up the same debugging tools on your server, wait for the issue to reproduce, and maybe get you the answer several weeks later.
We’ve been doing this kind of troubleshooting for years.
But to make it accessible to everyone who runs Microsoft web apps, we needed to do it automatically, with low overhead, and without requiring the user to be an IIS expert.
Here was our blueprint:
- Lightweight 24/7 monitoring to always catch problems the first time. We use performance counters, IIS logs, and ETW events to watch for problems. These protocols have near-zero overhead on the server, and cannot affect the application because they completely external.
- Automatically detect problems like hangs or memory leaks. These are the tricks of the trade: rules based on Microsoft guidelines and our own troubleshooting techniques. Our hang diagnostic uses over 12 different rules to reliably detect a hang given various pieces of lightweight monitoring data.
- Automatically analyze the problem so you don’t have to. When the problem is detected, we’ll analyze it immediately and attempt to determine the root cause. This also works to eliminate the knowledge gap: software can do the complex analysis and present the facts simply so that operations teams can easily act or transition the resolution to the developer.To do the analysis, we can leverage multiple data sources at our disposal: including IIS logs, ETW events, profiling data, and sometimes the debugger. We’ve been doing this kind of troubleshooting for years, so this was just a matter of automating it.Best of all, this analysis has low impact because a) it only takes place when there is already a problem and b) usually lasts just a few seconds and always keeps the application running.
- Alert you about the problem, and show you the solution. This is the best part. Instead of having to spend days hunting and analyzing the problem, you get a shrink-wrapped report with a pretty bow on it (bow not included). This is the difference between taking weeks to diagnose a problem every time, or literally minutes.
LeanSentry can now diagnose: website hangs, ASP.NET memory leaks, IIS application pool crashes, and more
Getting these kind of diagnostics to work right for everyone takes time. We are now 7 months after our launch in February, and here are the kinds of things we can diagnose:
- Hangs and slow page loads. We’ll detect IIS website hangs or very slow page loads, and tell you when you have concurrency misconfiguration problems or thread pool exhaustion. Down to the line of code thats causing the hang.
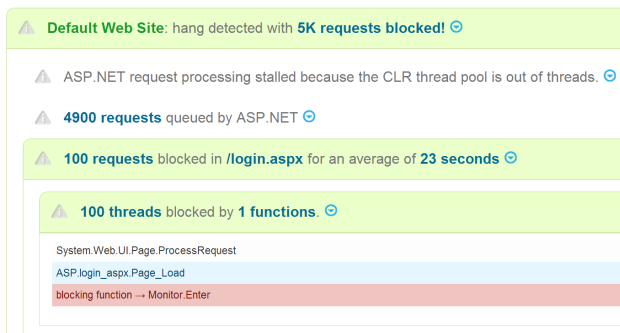 Learn more about the hang diagnostic →
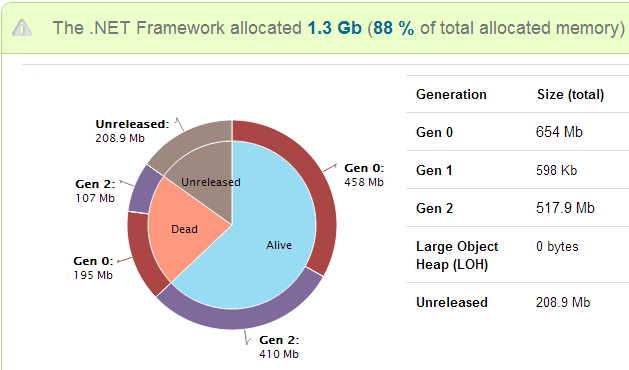
Learn more about the hang diagnostic → - ASP.NET memory leaks. We’ll detect memory leaks and out of memory problems, and give you a complete memory analysis to tell you what caused it.
 Learn more about the ASP.NET memory leak diagnostic →
Learn more about the ASP.NET memory leak diagnostic → - IIS and ASP.NET errors, IIS application pool crashes and recycles, and more.
There is too many to list here, but you can see many of them in action in our demo application.
Our ultimate goal was to change the way people deal with application problems in production.
To break the monitor -> struggle -> reproduce -> investigate cycle.
It looks like we are finally doing it. To check out our new diagnostics and how they work, go to www.leansentry.com. While there, set up a free trial account and never look back.