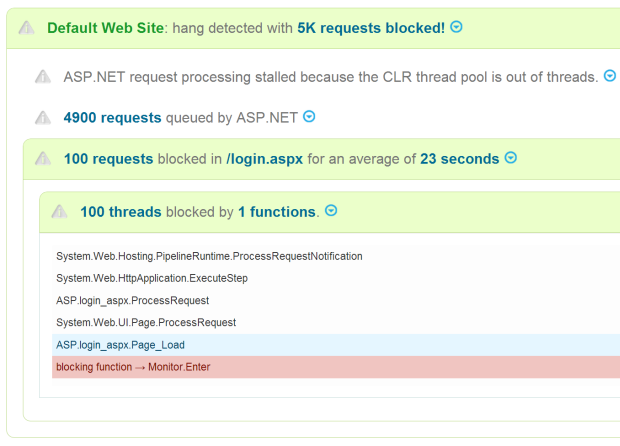
404 Not Found is the most common error for most production web applications. So, its all too easy to start ignoring them after a while.
After all, you can’t do anything about pages that don’t exist in your site, right?
WRONG. Turns out, 404 errors often signal real production problems that CAN and SHOULD be fixed.
Problems like:
- Broken links to your site that are causing you to lose potential sales or leads
- Botched deployment / code changes that prevent your users from using your site correctly
- Hacking activity that is wasting significant processing resources on your server
Read on to learn about the 4 common classes of 404 Not Found errors and what you should do to find and fix them.
LeanSentry tracks every single IIS and ASP.NET error for thousands of websites, and 404 Not Found is always at the top of the list. In fact, being able to ignore 404 errors has been a top LeanSentry feature request.
We’ve done a lot of work to help people track and fix production errors: grouping related errors, highlighting important errors, and letting the user quickly filter down to the errors they care about. While we dont advocate ignoring errors outright, we are also adding a feature to let you prioritize/hide specific errors for an app or just for a specific server / url.
The 4 classes of 404 errors you probably want to fix
Here are 4 key classes of 404 Not Found errors that require further attention, and how you can fix them:
1. Broken links to your site
Broken links to your site cause you to lose valuable leads, and frustrate your users. In some cases, bad links from major referral sources can cause you to lose a large percentage of your traffic.
How to find it
Look for 404 errors that request URLs that appear to “belong” to your site, e.g. following your site’s URL hierarchy or mispelling known versions of your urls.
How to fix it
Break the 404 errors by URL, and by HTTP Referer. You should be able to identify groups of specific content and referring sites that have the broken links.
NOTE: You need to turn on “Referer” field in your IIS logs to do this. It is unfortunately NOT enabled by default.
If the referrer is your own site, you can fix your own links. If the referrer is a third party site, you can contact them to get their links fixed.
2. Missing content, due to bad deployment or site changes
Bad deployments of your site content can cause some of your important content to become unavailable. Site changes often cause the same problem, esp. when URL rewriting or dynamic routing is involved.
How to find it
Look for 404 errors for URLs that previously worked.
How to fix it
You’ll need to diagnose the cause of the 404 error. This can be hard, since there can be many IIS and ASP.NET problems that lead to 404s (we’ll write another blog post about how to diagnose 404s comprehensively). Here are the top things to check:
1. Try to reproduce the 404 not found error yourself. Request the URL, if it returns a 404, great! You can now troubleshoot the error to figure out why. Be sure to use the detailed error page to confirm what physical file is being requested, and make sure it actually exists on the server.
2. Set up Failed Request Tracing to capture the 404 error trace. In the resulting traces, you should have all the details you need – the requested URL, phsysical resource it mapped to, the associated handler, and the error details.
3. Server routing errors
The server routing errors are becoming a more common problem, since many IIS/ASP.NET applications use SEO-friendly extensionless URLs, and code-determined routing (like ASP.NET MVC routing). A common time for these is a new code deployment or deployed to a new server, which can break both the configuration needed for routing and the code routing rules.
The process for finding and fixing this is similar to #2. However, a more detailed investigation may be required to understand why the routes are not working. The Failed Request Trace of the request may be a good start since it can trace URL Rewriter rule matching, and handler mapping done as part of routing. Also see this post for debugging ASP.NET MVC routing problems.
4. Hacking attempts
Many 404 errors are the result of hacking or bots scanning your website for vulnerabilities. I am sure everyone with a production website has seen the ubiquitous requests to “php_myadmin” even if they don’t have any PHP content.
You may want to dismiss these errors as “nothing you can do”. However, consider the following before moving on:
1. Requests to missing content can add significant processing overhead to your server. For example, they can cause worker processes to be started and ASP.NET applications to be loaded into memory / performing expensive initialization (this can be a big problem for servers that host many inactive applications).
2. Hacker requests failing with 404 not found errors may be a precursor to successful hacking attempts. You may want to stop them before its too late.
How to find it
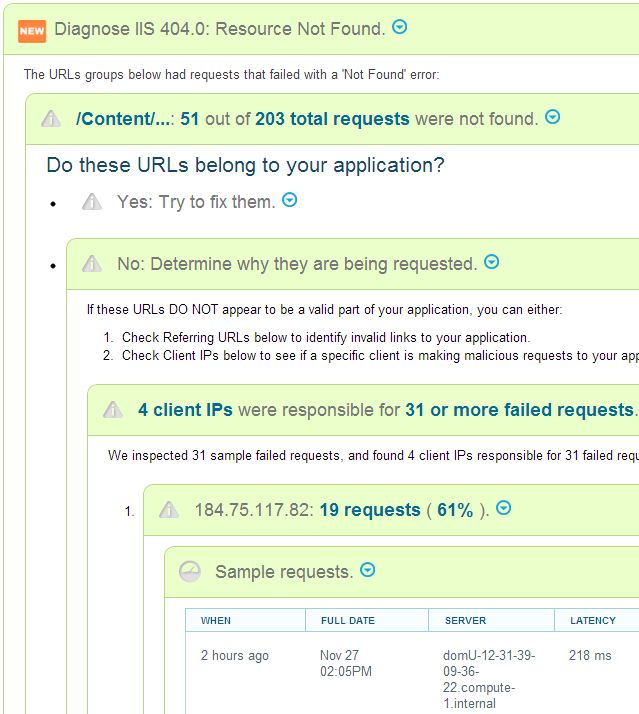
Break down your 404 errors by URL, and look for URLs that do not appear to be a legitimate part of your application. Specifically, look for URLs that have never been successfully requested.
Then, break down the 404 errors by client IP, by HTTP referer, and by User Agent. You will often be able to spot traffic from specific clients, or specific user agents, and this traffic will almost never have the HTTP referer set (be careful with jumping to conclusons if you dont have HTTP referer logging enabled).
How to fix it
To eliminate the impact of the traffic on your server, and to prevent hacking attempts, block the traffic you identify as malicious. Here are the top ideas:
1. Deny access to folders with authorization rules.
<location path="wp-cron.php">
<system.webServer>
<security>
<authorization>
<clear />
<add accessType="Deny" users="*" />
</authorization>
</security>
</system.webServer>
</location>
2. Implement IP blocking. You can use the IIS IP Restrictions feature, or the new Dynamic IP Restrictions feature.
Be proactive about monitoring and fixing errors
The best way to keep your website healthy is to watch the errors you have in production. Any time you see an increase in errors, or an increase in a specific error, you should investigate to see if there is a problem that can be fixed. By contrast, not watching errors or hoping that they will go away is a quick way to lose sales and frustrate your users.
Users don’t complain, they just leave. This was a lesson we learned early on after launching LeanSentry. After our initial launch, we had a ton of errors due to load problems with our backend. Once in a while, a user complained about the errors, and we fixed them.
However, eventually we realized that many users were just getting frustrated and leaving the site, without ever telling us about it.
So, we implemented a proactive strategy where we watched every single error, and followed up with every user that ever hit one. This helped us understand the true scale of the problems, fix them, and make sure that we stopped frustrated users from leaving.
LeanSentry is one great way to keep tabs on production errors in your IIS/ASP.NET applications. It tracks every single error, and groups related errors to give you an accurate history of how often the error happens.
What’s more, LeanSentry also solves the problem of troubleshooting the error, by capturing all the details you or your developers need to fix the error. Including ASP.NET exception callstacks, detailed request traces, and more.
To see how LeanSentry error tracking helps you get a handle on production errors, pop over to www.leansentry.com and check out the live demo! Then set up the free trial and never look back.